本章速通:数学分析 记忆佛脚(下) - Chapter 9 多元函数微分学 ↗
Section E 多元函数极值#
对于 f,若 ∀x∈Uρ(x^) 有 f(x)≤f(x^),则称 x^ 为 f 的极大值点。极小值类似定义
9.13 无条件极值#
曰(极值点的必要条件):若 f 可偏导,则偏导均为零,即 fx1(x^)=fx2(x^)=⋯=fxn(x^)=0
证明:
- 令 φ1(x)=(x,x^2,⋯,x^n),当 x^ 为 f 极值点时,由定义知 x^1 也得是 φ1(x) 的极值点,所以 fx1(x^)=φ1′(x^1)=0
- 令 φ2(x)=(x^1,x,⋯,x^n),当 x^ 为 f 极值点时,由定义知 x^2 也得是 φ2(x) 的极值点,所以 fx2(x^)=φ2′(x^2)=0
- 以此类推。□
极值情况判定定理。一元情形时:f′(x0)=0,f′′(x0)>0 时为极小,f′′(x0)<0 时为极大,f′′(x0)=0 时情况不定。这是因为 Taylor 公式 f(x0+Δx)−f(x0)=f′(x0)Δx+21f′′(x0+θΔx)Δx2,一阶导为零,所以等号左边是正是负就要看二阶导的正负。
二元情形:
f(x0+Δx,y0+Δy)−f(x0,y0)=fx(x0,y0)Δx+fy(x0,y0)Δy+21(fxx(ρ~)Δx2+fyy(ρ~)Δy2+2fxy(ρ~)ΔxΔy)
其中 ρ~=(x0+θΔx,y0+θΔy)
由连续性,设
- fxx(ρ~)=fxx(x0,y0)+α,α=o(1)
- fxy(ρ~)=fxy(x0,y0)+β,β=o(1)
- fyy(ρ~)=fyy(x0,y0)+γ,γ=o(1)
于是
f(x0+Δx,y0+Δy)−f(x0,y0)=21(fxx(x0,y0)Δx2+fyy(x0,y0)Δy2+2fxy(x0,y0)ΔxΔy+αΔx2+2βΔxΔy+γΔy2)
令
- A=fxx(x0,y0)、B=fxy(x0,y0)、C=fyy(x0,y0)
- ρ=Δx2+Δy2、ξ=ρΔx、η=ρΔy,这样 ξ2+η2=1
于是 f(x0+Δx,y0+Δy)−f(x0,y0)=21ρ2(Aξ2+2Bξη+Cη2+o(1))。括号里头就是一个二次型,所以等号左边的正负就相当于考虑右边二次型的定性(严格来说是在单位圆上的定性,但可以验证 g(kξ,kη)=k2g(ξ,η),所以等价于直接考虑在整个平面上的定性)。令二次型
g(ξ,η)=(ξη)(ABBC)(ξη)
- 当 g 正定时,(x0,y0) 为极小值点
- 当 g 负定时,(x0,y0) 为极大值点
- 当 g 不定时,既不是极大值点 又不是极小值点
回忆:正定负定的判断方法
- 正定:任一 k 阶顺序主子式的行列式都 >0
- 负定:任一 k 阶顺序主子式的行列式的 (−1)k 都 >0
对于二次型矩阵而言:
- 正定 ⇔A>0,AC−B2>0,则为极小值点
- 负定 ⇔A<0,AC−B2>0,则为极大值点
- 若 AC−B2<0,则不是极值点(鞍点)
- 若 AC−B2=0,则情况不定。例如 f(x,y)=x4 是极小值、−x4 是极大值、x3 不是极值
对于 n 元情形:那个二次型就是 g(ξ)=i,j∑fxixj(x^)ξiξj,二次型矩阵 (fxixj(x^))n×n 就是函数在 x^ 的二阶微分,称为 Hessian 矩阵。记它的 k 阶顺序主子式为 Δk:
- 当 ∀k,det(Δk)>0 时,g 正定,x^ 为极小值点
- 当 ∀k,(−1)kdet(Δk)>0 时,g 负定,x^ 为极大值点
- g 不定时,不是极值点
9.14 条件极值#
例:求原点到直线 l:{x+y+z=1x+2y+3z=6 的距离
称 f(z,y,z)=x2+y2+z2 为目标函数,{G(x,y,z)=x+y+z−1=0H(x,y,z)=x+2y+3z−6=0 为约束条件。于是问题转化为“求目标函数在约束条件下的最小值”。
设 f、G、H 偏导连续,Jacobi (GxHxGyHyGzHz) 在约束条件下秩为 2。不妨设 ∂(y,z)∂(G,H) 在极值点处不为 0,则唯一确定 {y=y(x)z=z(x),于是原问题转化为求 φ(x)=f(x,y(x),z(x)) 的无条件极值:
φ′(x)=fx+fy⋅y′(x)+fz⋅z′(x)=(fxfyfz)1y′z′=(gradf)⋅τ=0
把约束条件 G=0、H=0 也对 x 求导
{Gx+Gy⋅y′(x)+Gz⋅z′(x)=0⇒(gradG)⋅τ=0Hx+Hy⋅y′(x)+Hz⋅z′(x)=0⇒(gradH)⋅τ=0
这说明 gradf 落在 gradG 和 gradH 张成的平面里(因为事先假设过 Jacobi rank=2,这两个梯度不共线),于是存在常数 λ,μ 使得
gradf+λ⋅gradG+μ⋅gradH=0
展开 x,y,z 三个分量 就相当于三个方程,再加上两个约束 G=0、H=0,总共五个方程、x,y,z,λ,μ 五个未知数,因此原问题相当于求
L(x,y,z,λ,μ)=f(x,y,z)+λG(x,y,z)+μH(x,y,z)
这个五元函数的无条件极值,其中令 λ,μ 偏导为零 等价于 G=0,H=0
上述求条件极值的方法称为 Lagrange 乘子法。其中那个五元函数称为 Lagrange 函数,λ,μ 称为 Lagrange 乘子。由于还是基于无条件极值,所以这个方法给出的仍然是必要条件。
完整的 Lagrange 乘子法:
条件极值情况判定定理:考虑矩阵 (∂xi∂xj∂2L)n×n 在 Lagrange 函数极值点的定性,正定矩阵时为条件极小值点,负定矩阵时为条件极大值点,不定时情况不定。
为什么只看 x 不看 λ 呢?因为当满足约束时 G=0,得
L(x,λ)−L(x^,λ^)=(f(x)+λTG(x))−(f(x^)+λTG(x))=f(x)−f(x^)=21ρ2(二次型+o(1))
与 λ 无关
无条件极值情形下,矩阵不定表示 x^ 不是极值点;为什么这里矩阵不定表示 x^ 不定? 因为这里没看 λ
9.15 不等式约束与 KKT 条件#
对于优化问题
xmins.t.f(x)g(x)≤0
这个 g(x)≤0 就是不等式约束。定义可行域:满足不等式约束的 x 的集合,记为 K
我们先强行把 g 看作等式约束。写出该问题的 Lagrange 函数
L(x,λ)=f(x)+λg(x)
由 Lagrange 乘子法,最优解 x^ 的必要条件是 ∇f(x^)+λ∇g(x^)=0。把这个解代回原问题,讨论这个最优解是否受到不等式约束的影响:
- 若 g(x^)<0(内部解),此时约束恒成立,相当于没有这个约束(称为松弛的)。说明 x^ 已经是 f 的极小值,也即 ∇f=0,因此 Lagrange 乘子 λ 只能 =0
- 若 g(x^)=0(边界解),说明 g(x) 约束的存在拦住了 f 继续变小的道路,使得 x^ 停了下来。
也就是说,不管 x^ 是否在边界,g(x^) 和 λ 必有一个是 0,即 λg(x^)=0。这被称为互补松弛条件。
还不够。对于边界解的 λ 还要有所限制。如下图所示,其中一圈一圈的代表 f 的等高线、弧线代表 g(x)=0。最优解 x^ 被 g(x)=0 这条墙拦住了去路,说明这个地方 x^ 本来还想往下走的,因此 ∇f(x^) 一定指向 K 的内部;可行域内部 g(x)<0,所以 ∇g(x^) 指向 K 的外部。而 Lagrange 乘子法又说 ∇f+λ∇g=0,因此这个 λ 必须 ≥0。
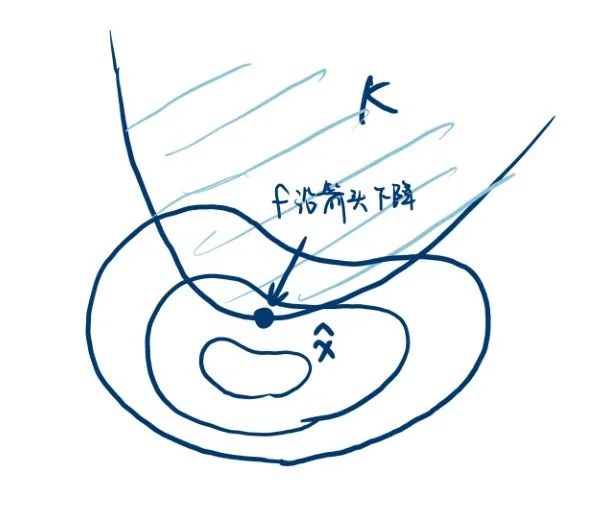
也就是说,极值点的必要条件为(略去 hat 号,相当于解方程):
- Lagrange 函数偏导得 0:∇f+λ∇g=0
- 原始约束:g(x)≤0
- 互补松弛条件:λg(x)=0
- 梯度方向限制:λ≥0
这四个条件,合称为 KKT 条件(Karush-Kuhn-Tucker)。
加入多个不等式约束、再加入等式约束,完整版的 KKT 长这样