编译引论#
编程语言#
命令式语言:C/Python,通过明确的步骤和状态变化控制计算机行为
声明式语言:SQL,只讲目标不讲中间步骤
静态类型语言:运行前/编译时进行类型检查,C
动态类型语言:运行时进行类型检查,Python
强类型语言:不允许隐式数据类型转换,Python
弱类型语言:允许隐式数据类型转换,C
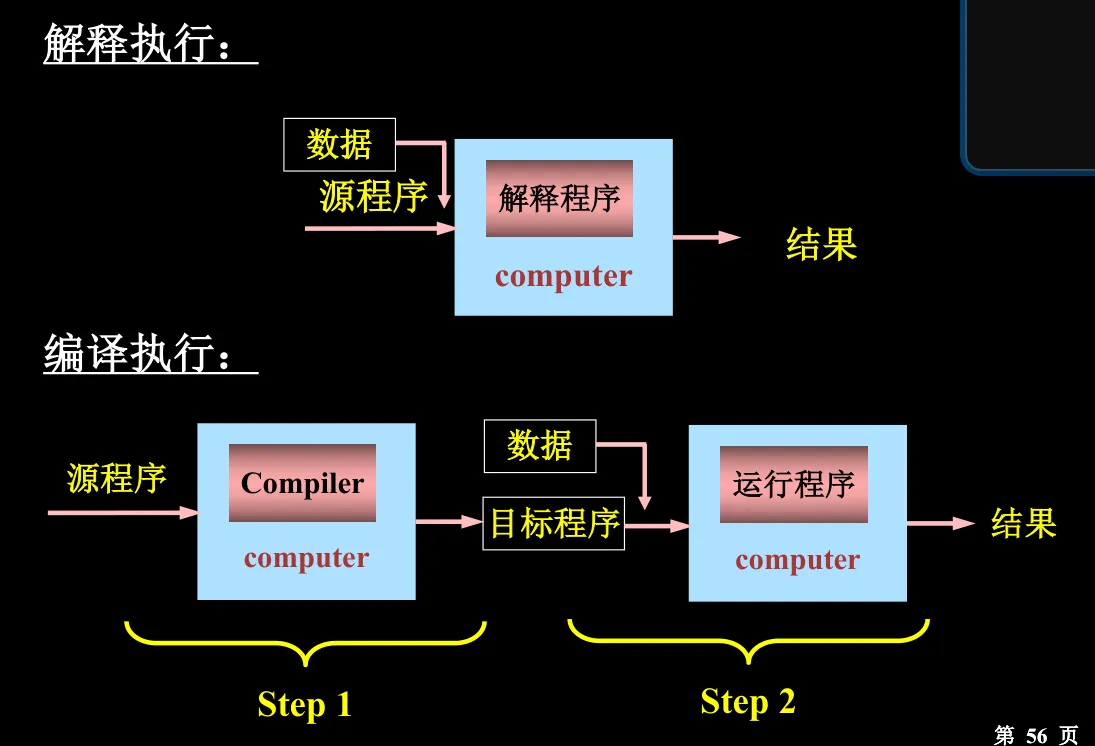
编译型语言:要用编译器转换为机器码(二进制文件),可以直接在目标机器上运行,执行速度快。不能跨平台,只能重新编译
解释型语言:由解释器逐行读取并执行,不生成中间文件,执行速度慢。跨平台性强,只要目标机器有对应的解释器)
程序设计语言与编译程序#
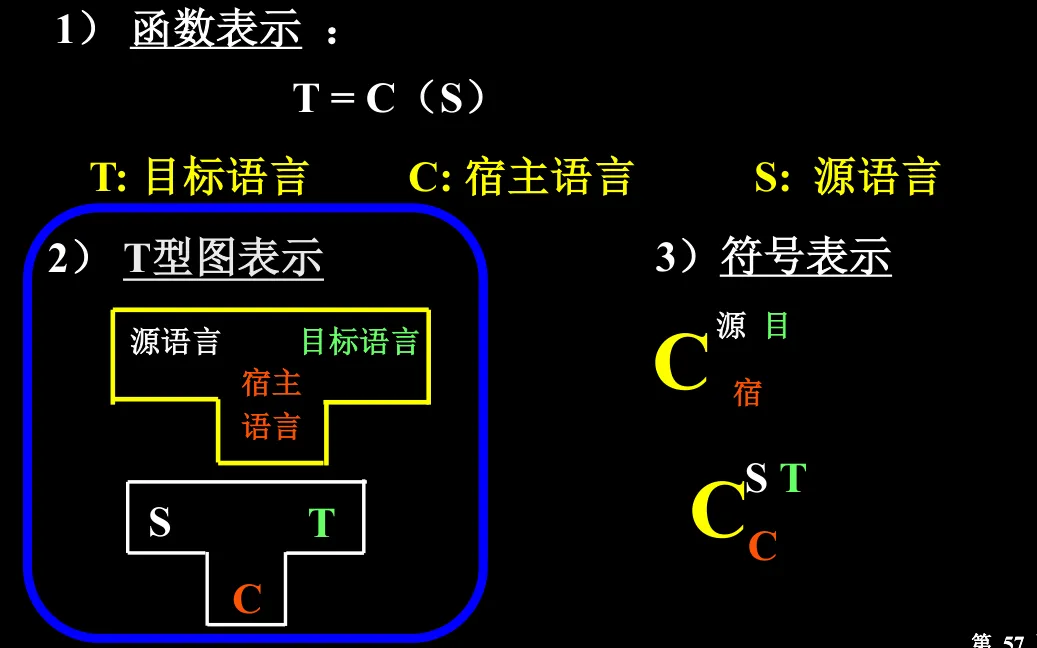
源程序,经过编译器(一个程序),变成等价的目标程序
源程序 是用 源语言 描述的
编译器 是用 宿主语言 描述的,运行在宿主机上
目标程序 是用 目标语言 描述的
编译程序的表示#
组合:编译程序之间的转换,将以 C 为宿主语言编写的 A->B 编译程序,转化为以 L 为宿主语言的 A->B 编译程序
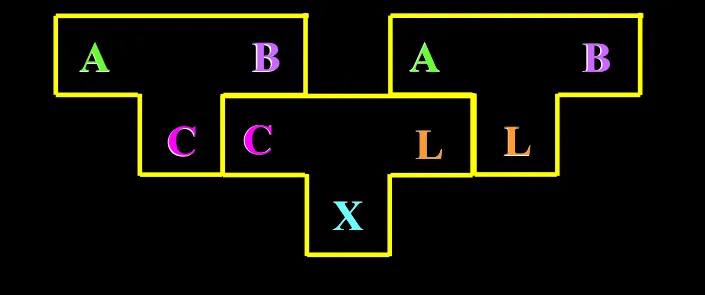
这个图的意思是,已知中间的和左边的,我就可以得到右边的。
- 左边和右边,源语言和目标语言是一致的,都是 A->B
- 左边的宿主语言一定是中间的源语言,右边的宿主语言一定是中间的目标语言
必考
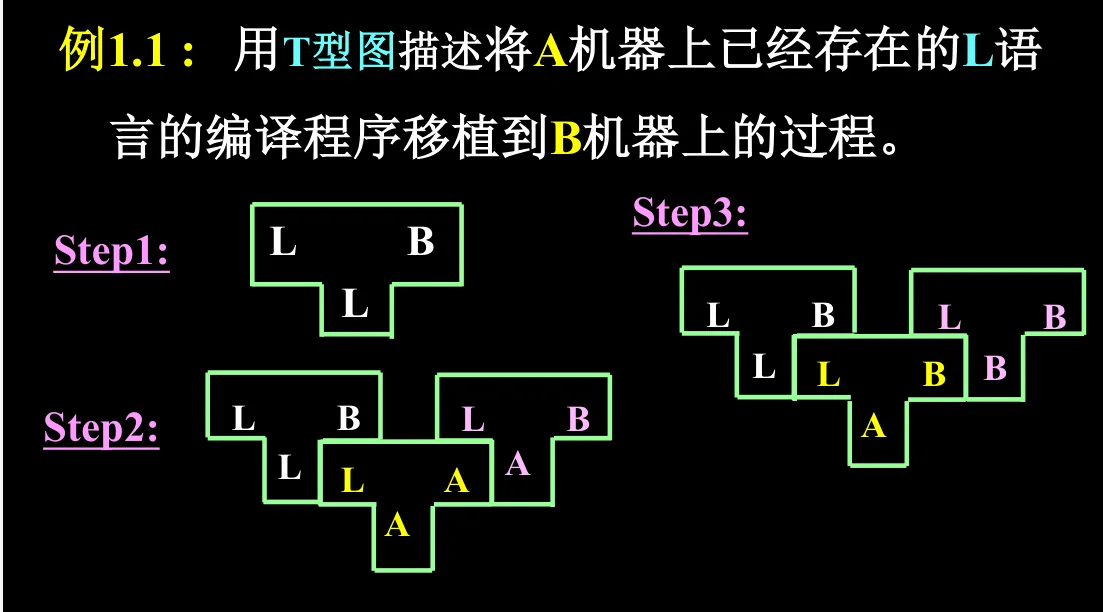
这类题目故意隐去的前提:
- 我们不可能直接写出一个“宿主语言是 A 或 B 的编译程序”,因为 A 和 B 一般会是汇编甚至直接是 01 二进制代码,所以我们不能直接写出一个 L-(B)->B 的编译器
- 不论哪个组合,中间的 T 形图的其宿主语言一定得是 A 或者 B,因为必须要在某个机器上运行起来,而 L 是不能单独运行起来的。结合第一条可知,这个中间的 T 形图,要么是题目已知的,要么是我们通过另一个组合得到的
- A 机器上运行的 L 语言的编译程序,指的是 L-(A)->A
题目上已知 L-(A)->A,我们的最终目标是 L-(B)->B,因此最后一步一定是 L->(1)->B、2-(3)->B、L-(B)->B。现在就来填未知的这 123。
- 1 是 L,因为 A 和 B 不能做宿主语言
- 2 是 1,因为左边的宿主语言一定是中间的源语言,所以 2 是 L
- 3 是 A,因为中间的宿主语言一定是 A 或 B,而如果是 B 的话,中间和右边就重复了
于是最后一步就出来了:L-(L)->B、L-(A)->B、L-(B)->B
因此我只需要搞出 L-(L)->B 和 L-(A)->B。L-(L)->B 直接就可以写,因为宿主语言不是 A 或 B。而 L-(A)->B 就要再迂回一下,因此还需要前置一步 L->(1)->B、2-(3)->A、L-(A)->B
- 1 是 L,因为 A 和 B 不能做宿主语言
- 2 是 1,因为左边的宿主语言一定是中间的源语言,所以 2 是 L
- 3 是 A,因为因为中间的宿主语言一定是 A 或 B,由于我们题上已知了 L-(A)->A,直接用就行了,根本不要考虑 3 是 B 的可能性,即使有我们也不用。
于是这步前置也出来了 L-(L)->B、L-(A)->A、L-(A)->B
所有东西都是已知的了,这就是题上三步骤的由来。把三个步骤写到一起:
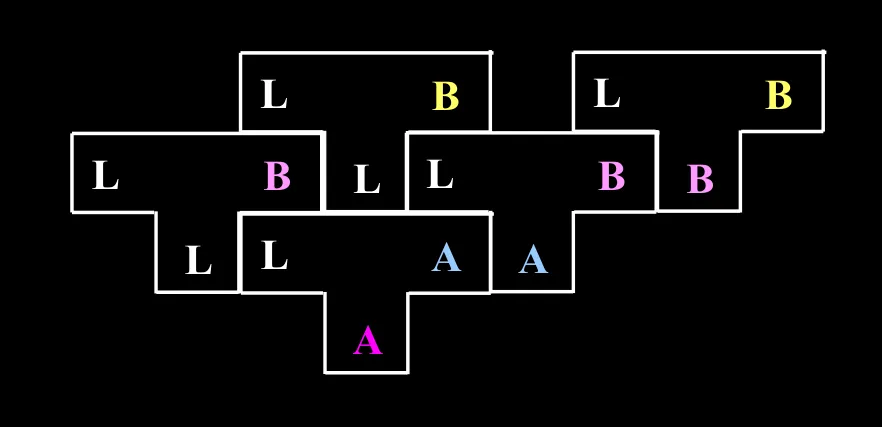
直接写这个图更快,反复嵌套“未知编译器”就行了,实在不行背下来
编译程序的结构#
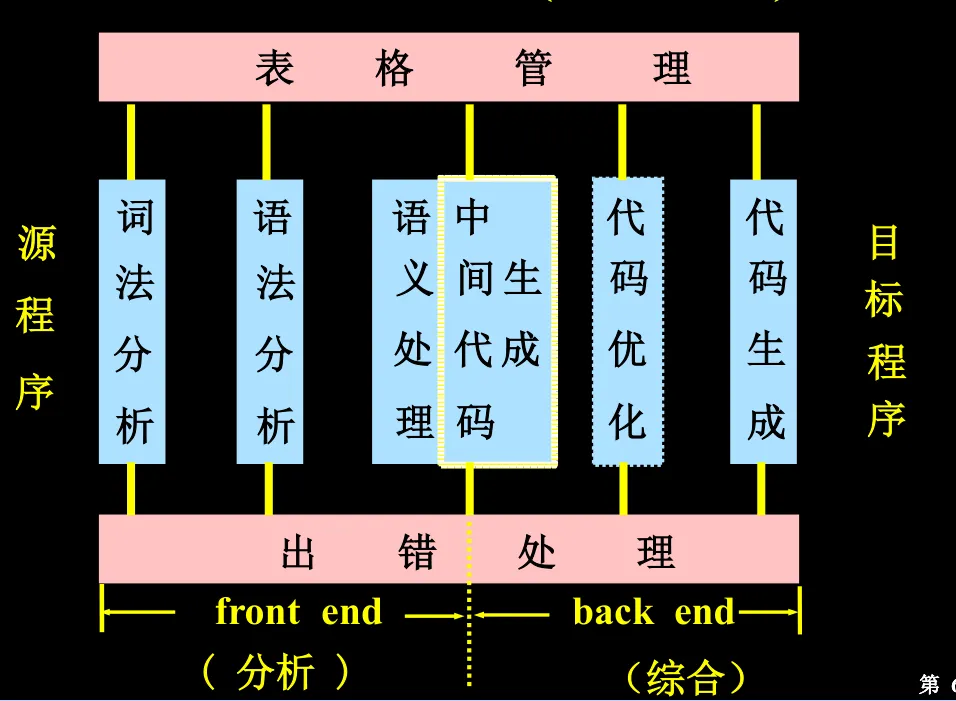
编译程序的逻辑结构的经典划分
词法分析:依据词法规则,将源字符串中有独立意义的单词识别出来。识别结果是一个二元组(属性字),表示这个单词的属性(类型标识)以及值(内码,可以为空)

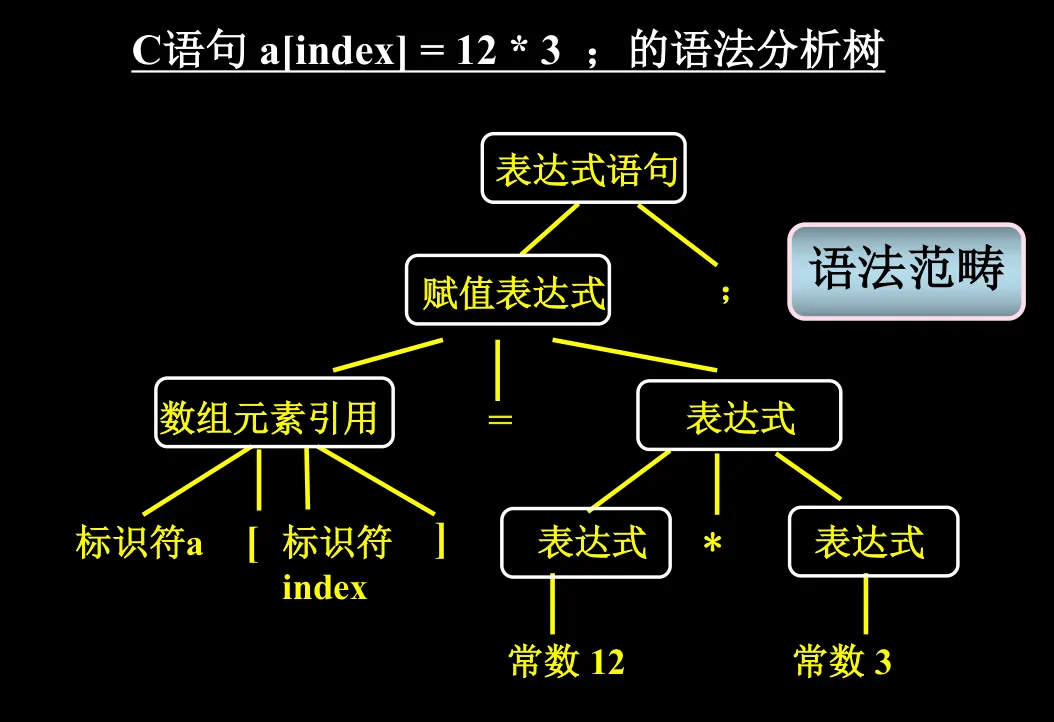
语法分析:依据语法规则,将线性的属性字流转化为语法分析树。比如下面这个语法,“数组元素引用”这个语法包含四个元素,标识符 + 左中括号 + 标识符 + 右中括号;所以反过来说,只要出现“标识符 + 左中括号 + 标识符 + 右中括号”这个组合,就可以归约为一个“数组元素引用”。只要能从属性字流中生成一个语法分析树,就说明这个属性字流是合法的
语义分析:依据语义规则,将语法树进行处理, 翻译成等价的中间代码或目标代码(四元式序列)。刚才的两步只是拆解,语义分析才是整个编译程序完成的最实质性的翻译任务。比如表达式 a+b=c 翻译为汇编语言 ADD A B C。在语义分析之前,你根本不知道“+”这个字符是什么意思;同样的,前面只知道“while(表达式)”这几个东西要合在一起,但不知道为什么是要做循环

代码优化:不改变源程序语义的基础上,对四元式序列加工变换, 以期获得高效的目标代码。比如下面这个,说的就是“对于常数,在编译阶段就会算好,节省一步四元式的计算”

代码生成不考
表格管理 + 出错处理,这两个是各阶段都要涉及到的。
- 表格管理:对各种量进行管理,登记在相应的表格。处理时通过查表得到所需的信息。
- 出错处理:对源程序中的各种错误检查、定位、定性、报告, 尽可能将错误限制在尽可能小的范围内, 保障编译能够继续运行。当然新时代的出错处理已经是“通过大模型直接把错误给改对了”
“一遍”,指的是将源程序从头到尾扫描一次。一个编译程序可能有很多“遍”
编译程序结构的实例模型#
要构造一个编译程序,必须掌握的三要素为?
源语言
目标语言
编译方法、技术与工具
编译程序的生成方式:使用编程语言;移植方式; 自编译 (用源语言作为宿主语言)
词法分析#
流程:正规集 NFA DFA 最小 DFA 词法分析器代码
正规式与正规集#
字符串:由有限个字母或空串拼成的。字符串的长度不可能是无限长的
语言:字符串的集合
防止考定义:

空串 ,只含有一个空串的集合 ,这个不是空集
串长度


串的前缀、后缀和子串
- 前缀:串的前面连续几个字母,可以是空,可以是自身。不是自身的时候称为真前缀
- 后缀:串的后面连续几个字母,可以是空,可以是自身。不是自身的时候称为真后缀
- 子串:串的中间连续几个字母,可以是空,可以是自身,可以是前缀,可以是后缀
- 只要不连续,就啥也不是
用希腊字母表示字符串,英文字母表示字母
串的乘积(直接拼接)、方幂
串集合的乘积:所有拼接排列组合、方幂

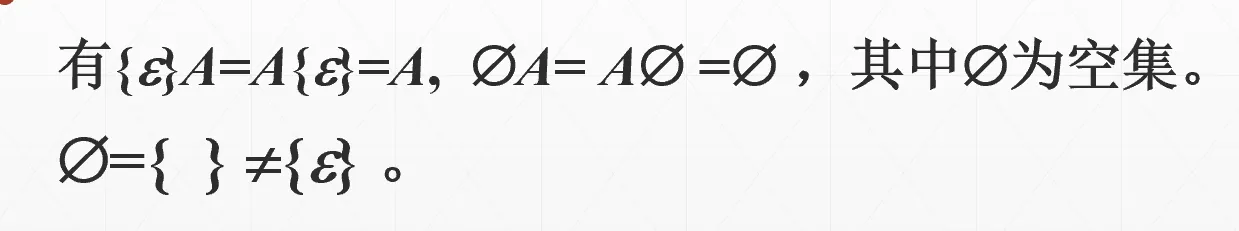
注意:
- 串的零次幂
- 串集合的零次幂
串集合的闭包
- 正闭包:
- 自反闭包:,也就是比正闭包多一个 这个元素
会说含义,会算长度

正规式:是一个特殊的字符串(严格来说不是字符串,因为这里头的括号、竖线、星号都是附加的字母,不在字母表里头),用来描述一个串集,称为这个正规式对应的正规集。正规式有三个操作,得到新的正规式对应的正规集的构造如下
- 或操作 ,表示“将两个正规式表示的正规集取并集”
- 连接操作 ,表示“将两个正规式表示的正规集相乘”
- 闭包操作 ,表示“将这个正规式表示的正规集做闭包”
正规式是由字母或空串经过有限次的“或”“连接”“闭包”操作得到的
特殊:
- 空串 是正规式,描述的正规集为 ;
- 为了让正规集 也能被正规式描述,我们让 作为 的正规式
防止考定义:

例子


正规式 表达了一个正规集 ,也即表达了一个字符串的集合。而语言就是字符串的集合,因此正规式描述了一个语言,这称为正规式 的正则语言
中的元素称为单词或句子。
若两个正规式所表示的语言相等,也即正规集相等,则称这两个正规式等价。例如 和 这两个正规式不相等,但是表达的正规集是相等的
有限自动机#
DFA#
确定的有限自动机
,状态集、字母表、状态转移函数、初态、终态集
三种表示方式:状态转移函数、状态转换图、状态转换表,三者等价
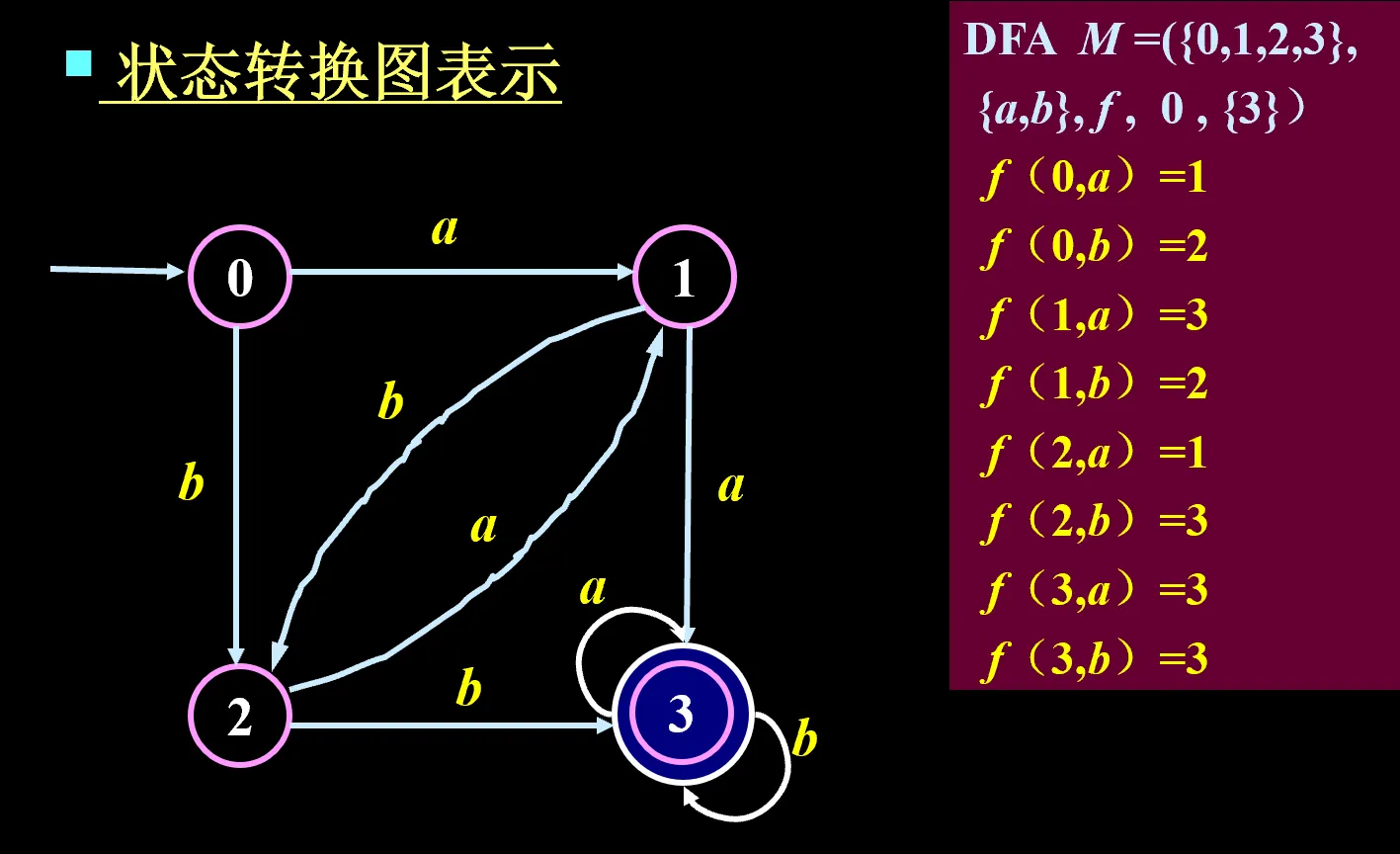
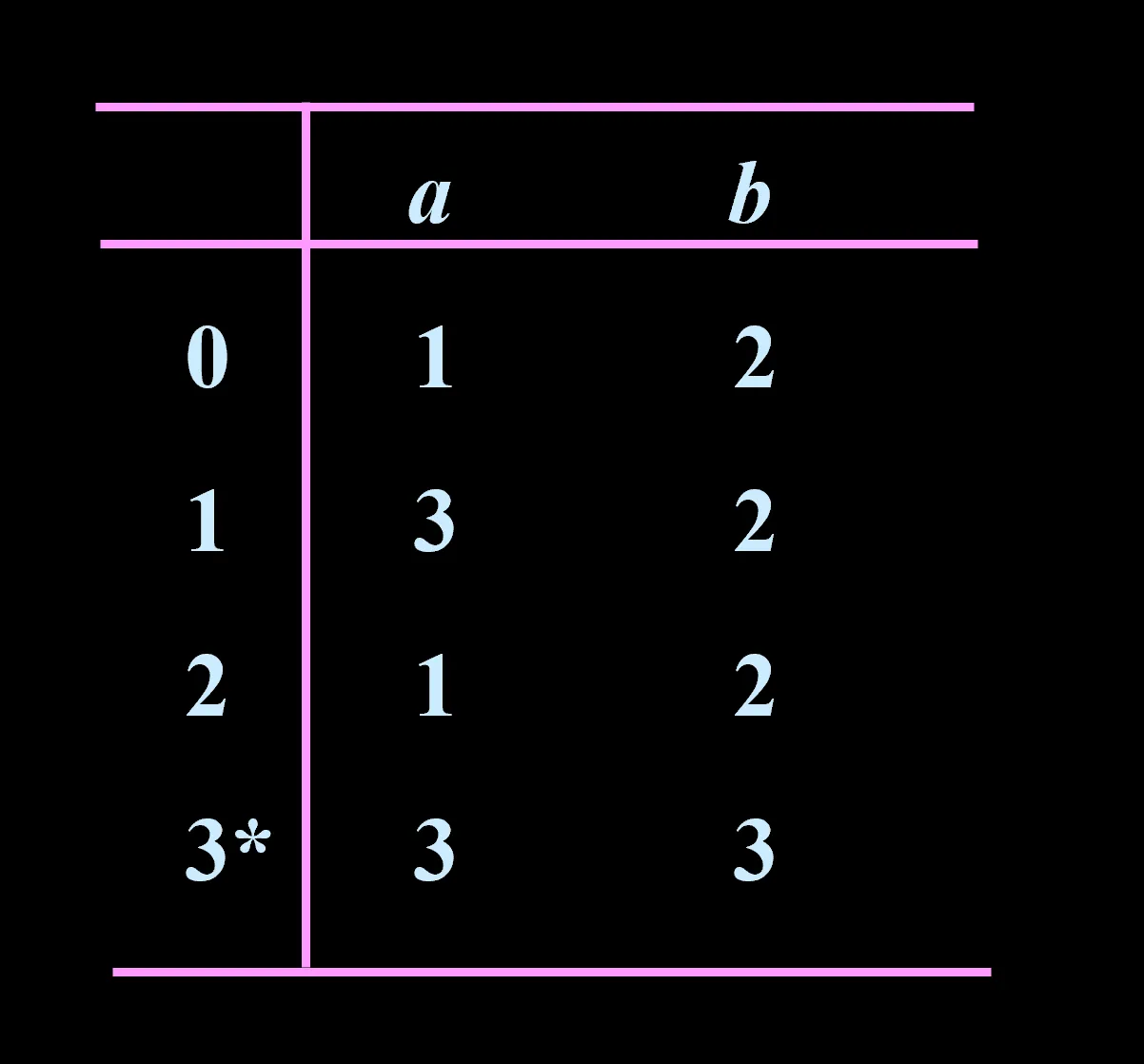
DFA 的识别机制
对于字符串 ,一个字母一个字母地进入 DFA,如果读完之后落在终态,代表这个 DFA 能接受这个 ,否则不接受。特别地,如果初态就是终态,则接受空串
记号描述:,表示从初态开始,每次读入 的一个字母,最后落到的那个状态,也即
如果 ,则字符串 能被接受
DFA 所识别的字符串的全体称为 M 识别的语言,记为 。也即 ,当然还有一个要求是
分析过程书写格式
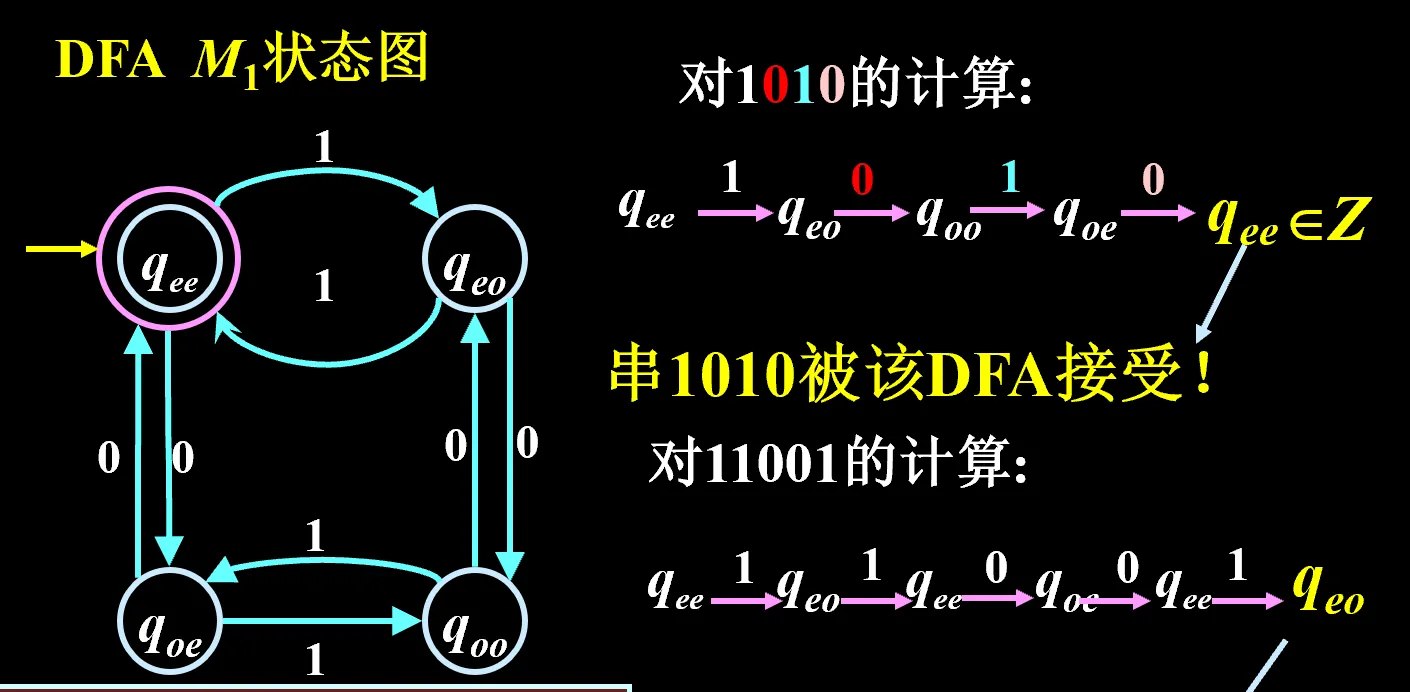
例子:
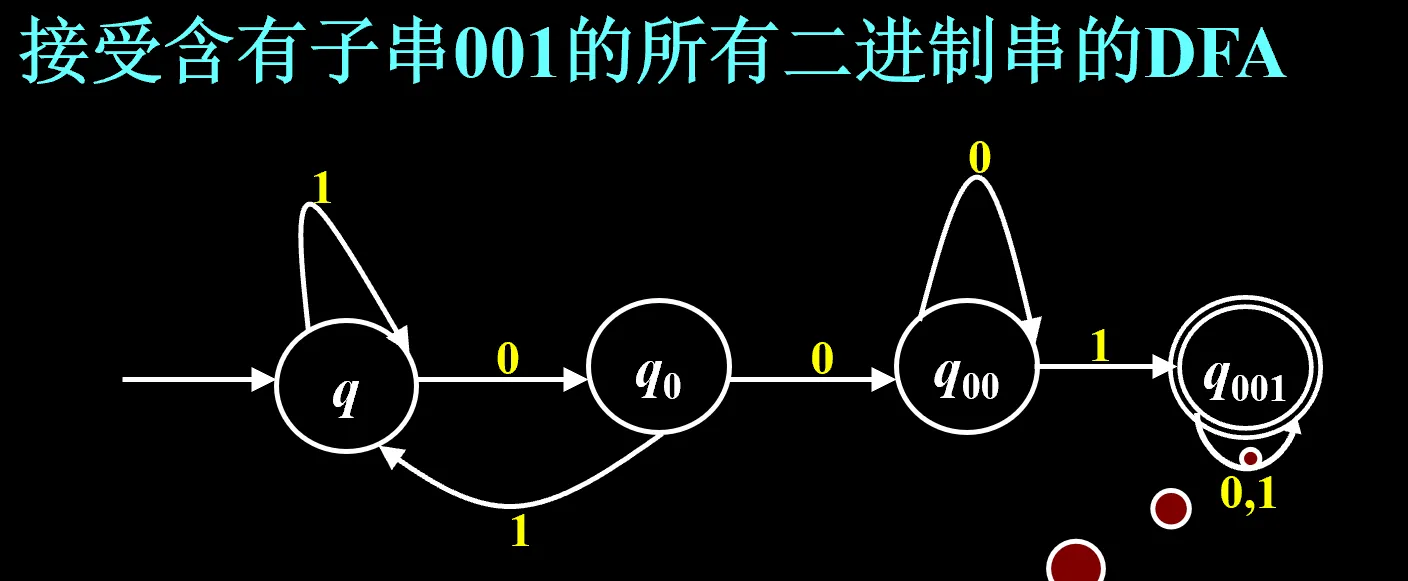
如果改成“接受不含有子串 001 的所有二进制串的 DFA”,只需要把这个图的终态改成前三个、第四个不是终态就行了
NFA#
非确定的有限自动机
例如 c 语言中,读入一个加号,你不知道这是加号、还是 ++、还是 +=
依然是五元组 ,区别在于
- DFA 中
- NFA 中 ,也即 NFA 可以读入空字符,而且不是映射到一个具体的状态,而是映射到一个状态集。比如说 ,就是说状态 读入字符 之后可以转移到 当中的任意一个状态, 中的任意一个状态都称为 的后继状态。若 则不需要读入字符就可以转化到 中的任意一个状态。
特别地,如果 ,那么相当于直接卡住了,无法再读入一个新的字母
NFA 的识别机制, 和 DFA 是类似的,只要存在一条路径使得最后落在终态,我就接受这个字符串。验证路径可能不止一条
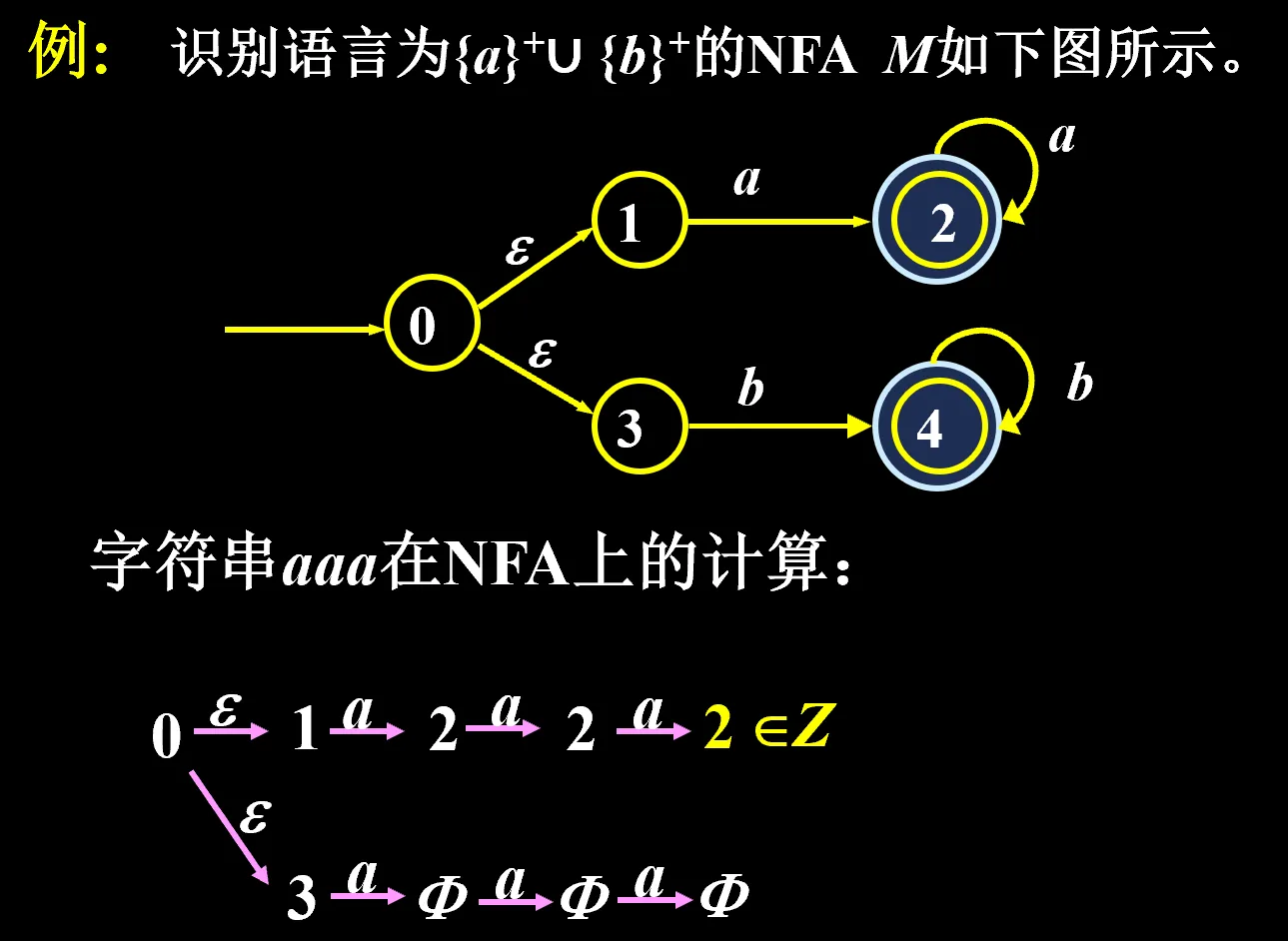
设计一个

NFA 的确定化#
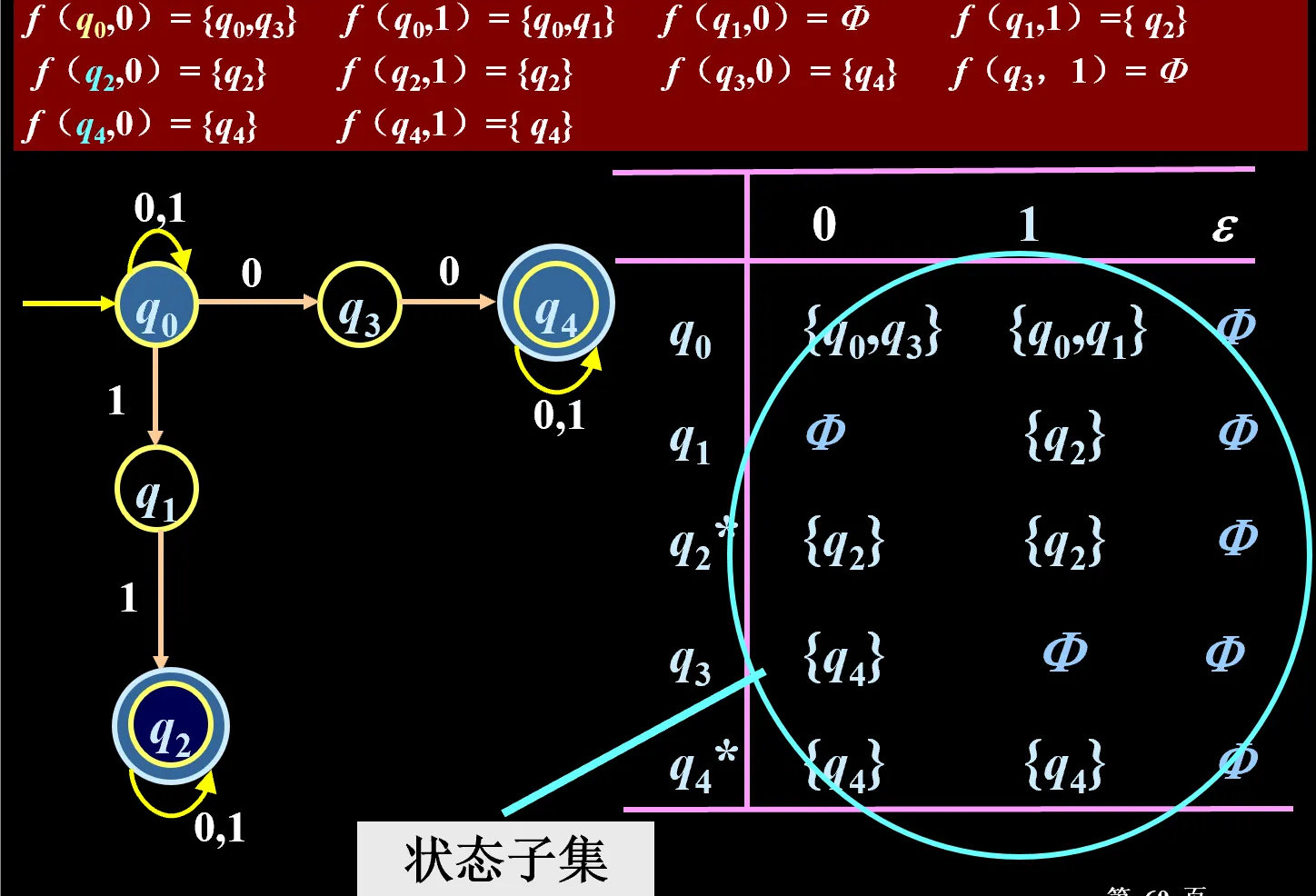
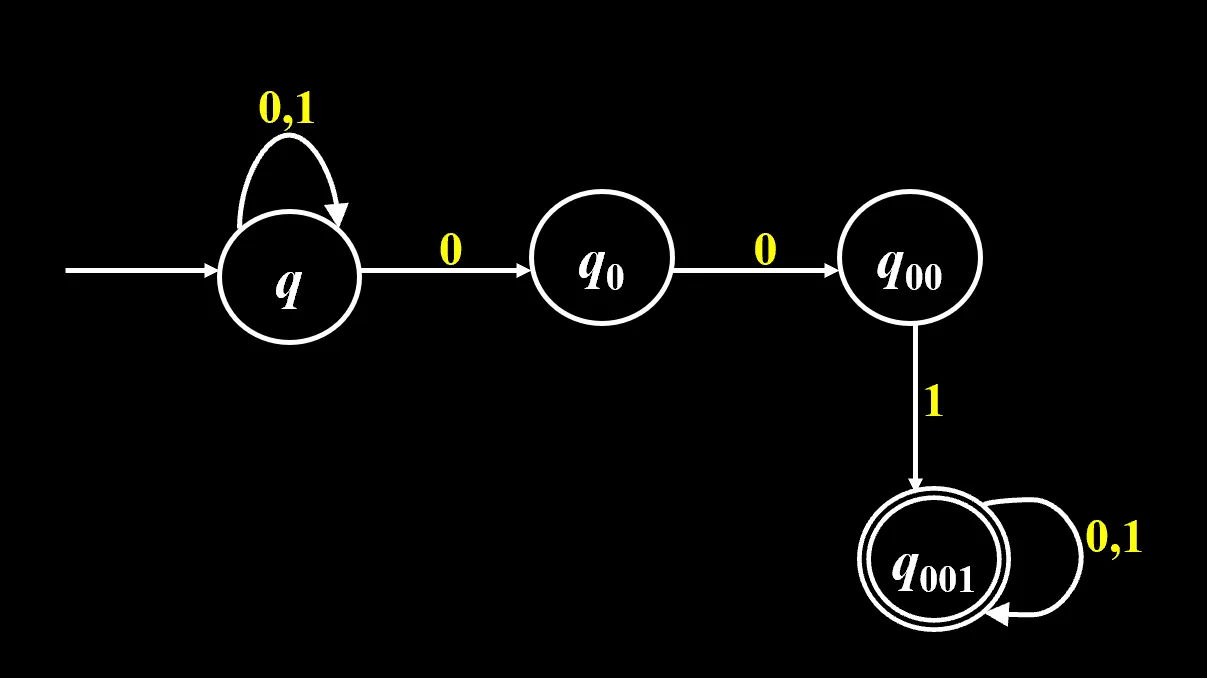
曰:任何一个 NFA ,都存在一个 DFA 使得他们两个能接受的语言是一样的。
定义:状态集 的 闭包:在 中的状态下,不读任何字符就能到达的状态的全体。
构造方法:
- 设置一个空的“状态集”集,这里头的每个 NFA 状态集都是 DFA 的一个状态
- 从原来的 开始,将原来由 联系起来的状态合成一个新的初始状态,加入“状态集”集
- 遍历“状态集”集,遍历字母表,得到一步之后的新状态集,加入“状态集”集
- 直到不再出现新的状态集
- 含有终态集中元素的状态集就是 DFA 的终态

先求接受这个字符之后的集合,然后再求ε闭包
最终的 DFA 状态转移表就长这样
表示 ,称为 a 弧转化
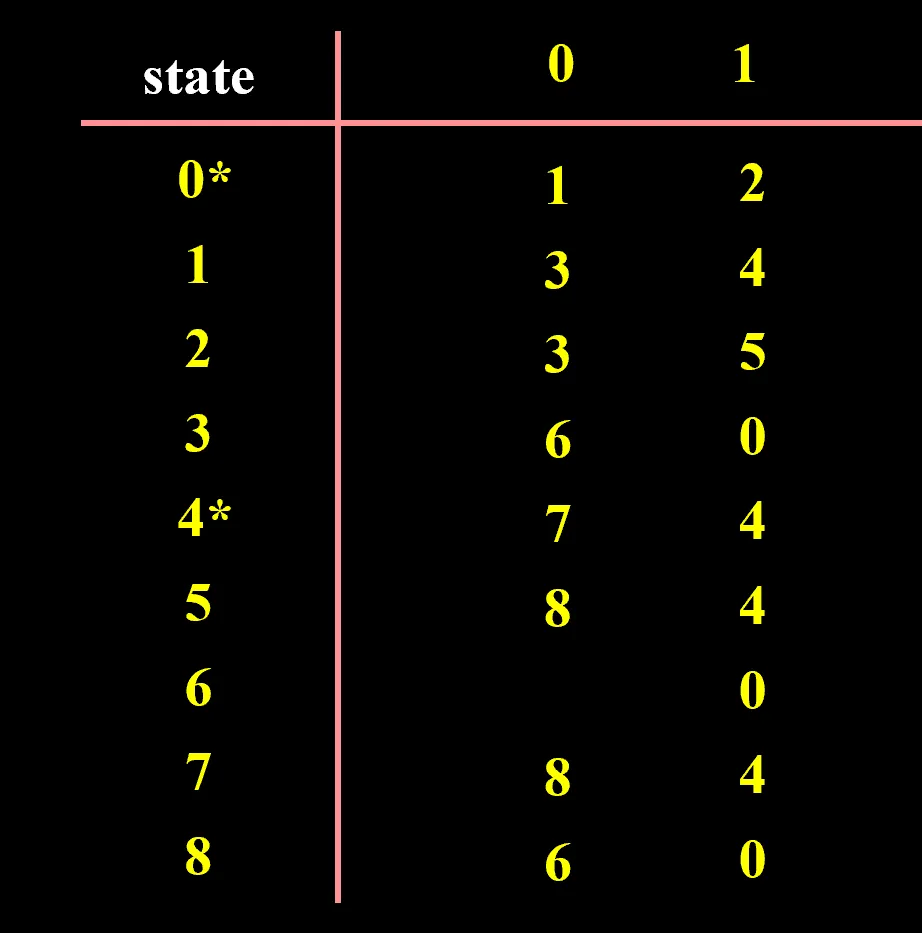
DFA 的最小化#
曰:对于任意一个语言 ,存在一个状态数最小的 DFA 使得 。这个新的 DFA 当中没有无关状态,也没有彼此等价的状态,称这个 DFA 是“归约的”
定义:无关状态:从 开始,任何输入序列都不能到达的那些状态。方法:直接看表,从初态 0 开始一个一个看,存在过的则有关,直到做到最后都不离开有关状态集
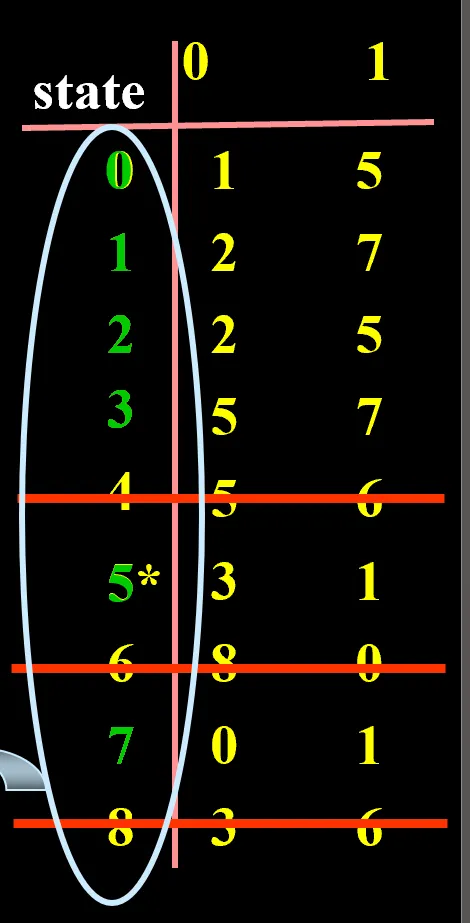
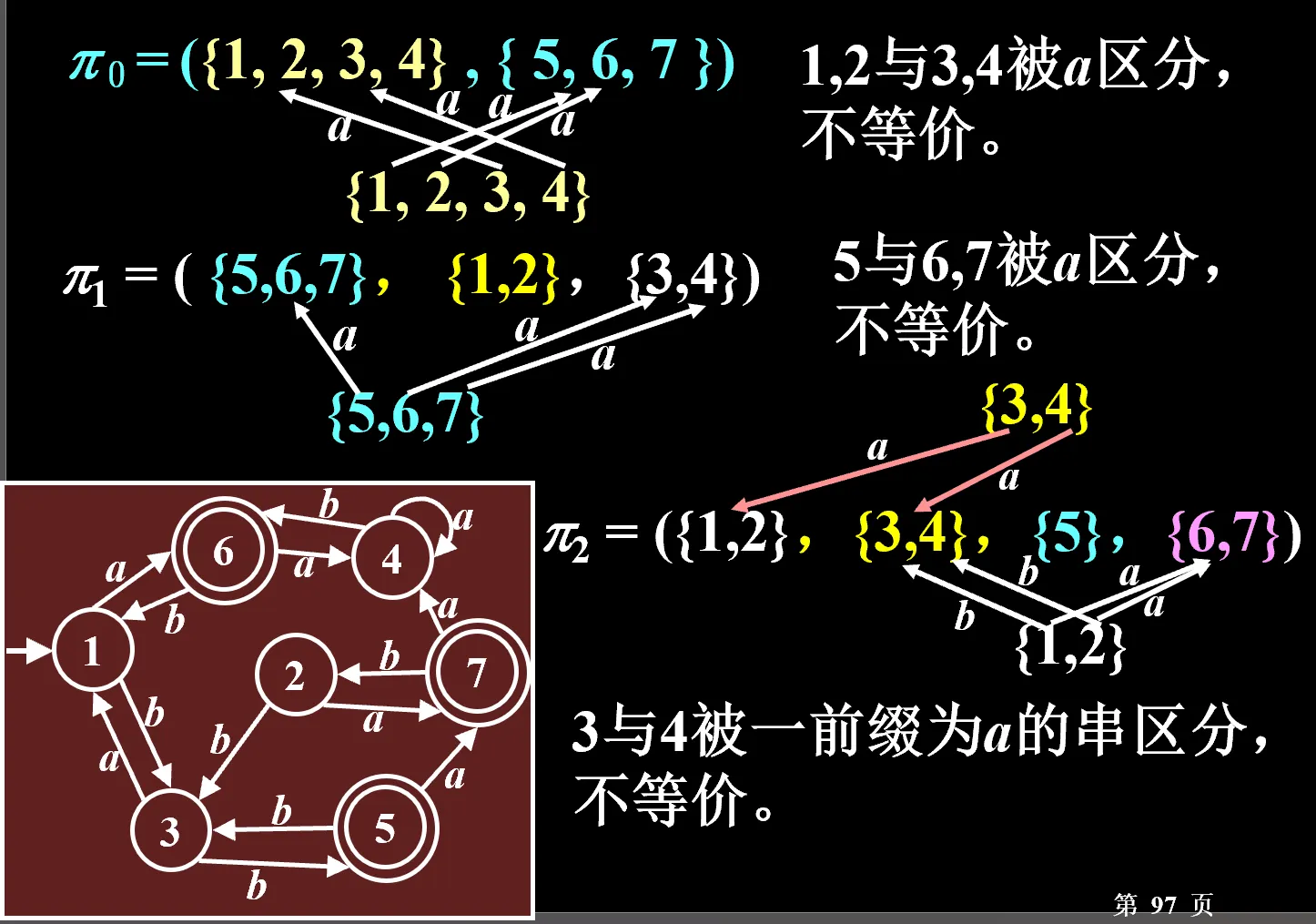
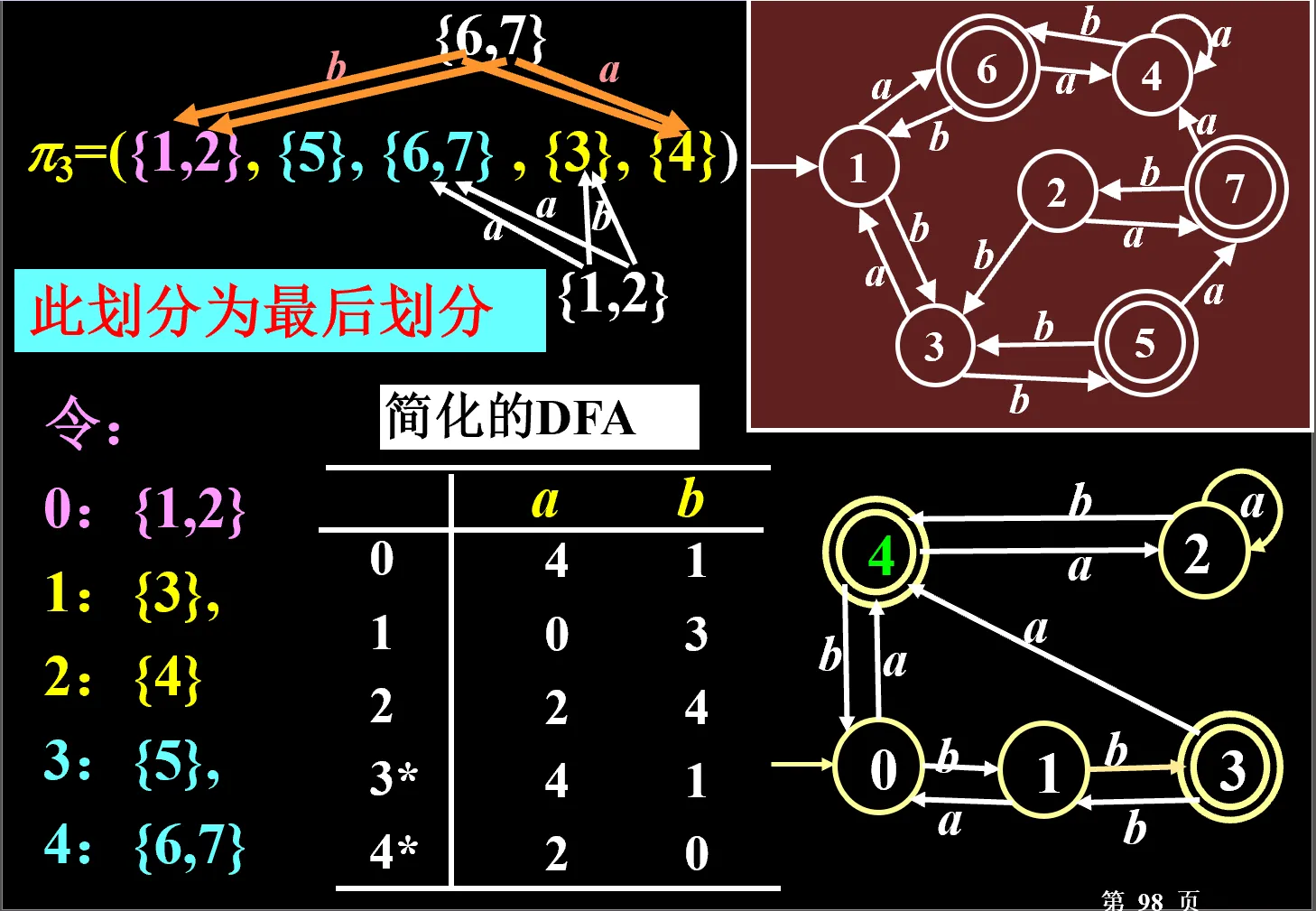
定义:等价状态:从 q1,q2 状态出发,对任意输入字符串,总是同时到达接收状态或拒绝状态之中,称 q1,q2 是等价的。否则称 q1,q2 不等价。方法:划分法。
将状态集划分为几个块,每一块是将来 M’ 的一个状态
0. 对每一块,判断每一块里头的状态是否等价(也就是加同样一个字母之后,是否到达同一个块),把不等价的状态划分到不同的子集,形成新的划分
- 一开始将状态集划分为“终态集”和“非终态集”
- 重复步骤零中的操作,直到划分不再变化
- 划分出来的每一块是一个新状态。含有原来初态的就是初态,含有原来终态的就是终态
正规式与有限自动机#
曰:FA 接受的语言是一个正规集,也即存在一个正规式使得
(推论曰:串集 是正规的,当且仅当存在 st ¥ )
从 FA 到正规式#
方法:从 FA 的原始状态图开始,变成只有两个状态,中间连线上的表达式就是这个 FA 对应的正规式
- 增加初态节点 ,通过ε接到
- 增加终态节点 ,原来的所有终态都通过ε接到
- 按照替换规则化简,直到只剩 和 两个结点
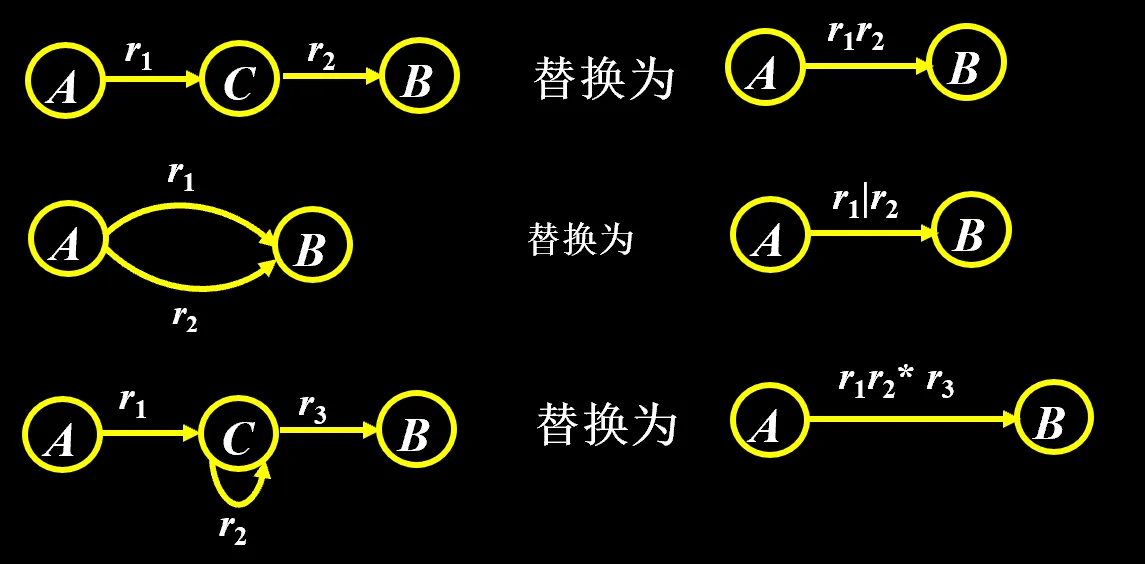
中间随时可以等价化简,看正规式化简规则
正规式运算规则

还有几条常用的
写正规式的例子:
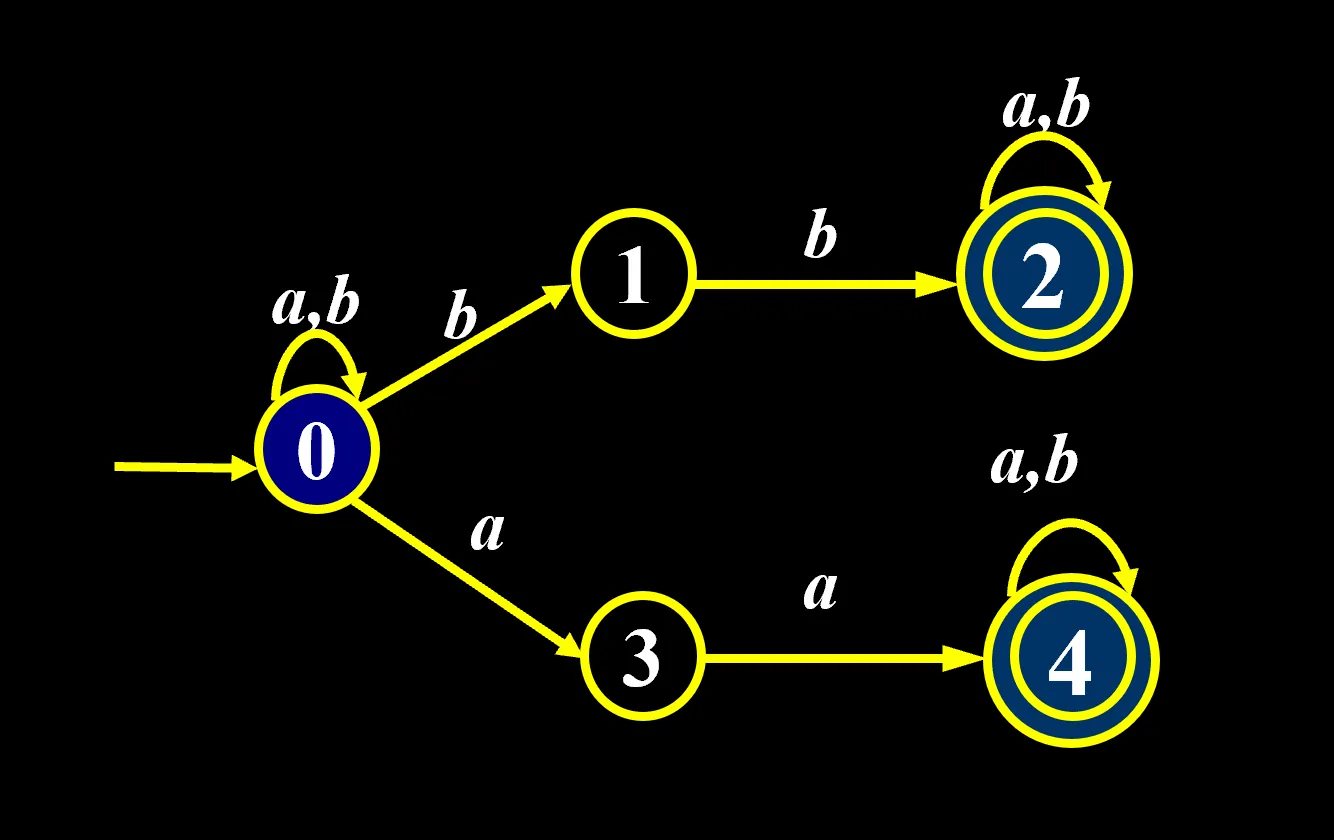
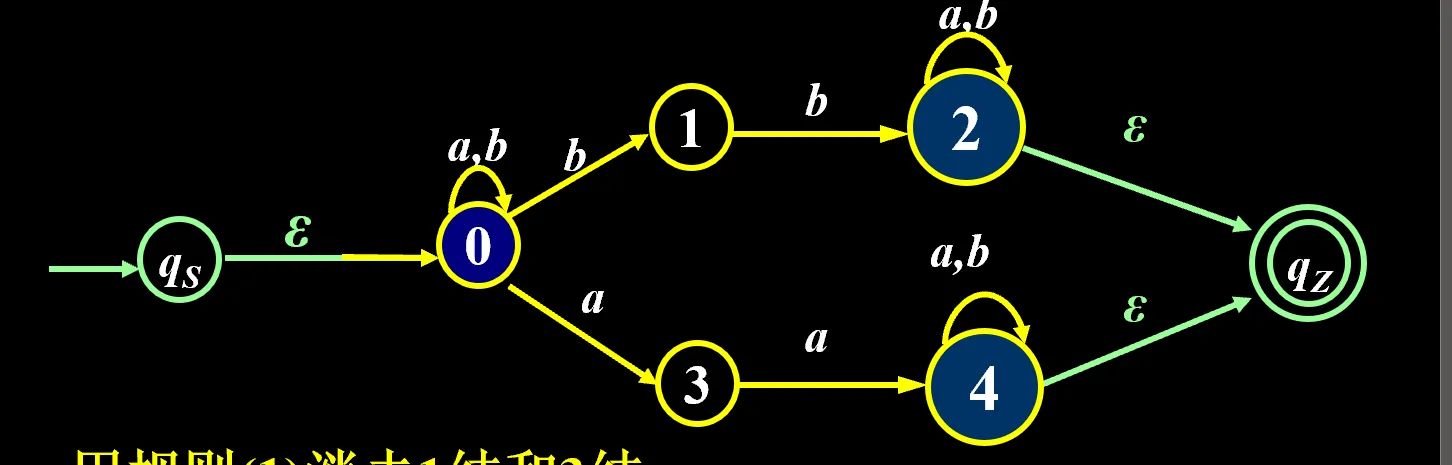
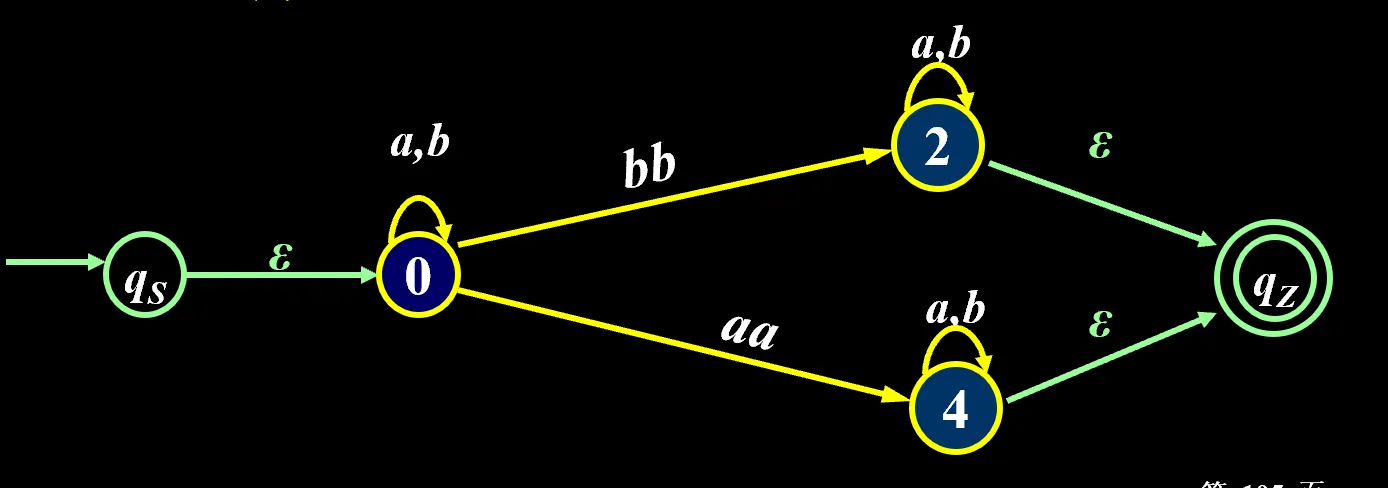
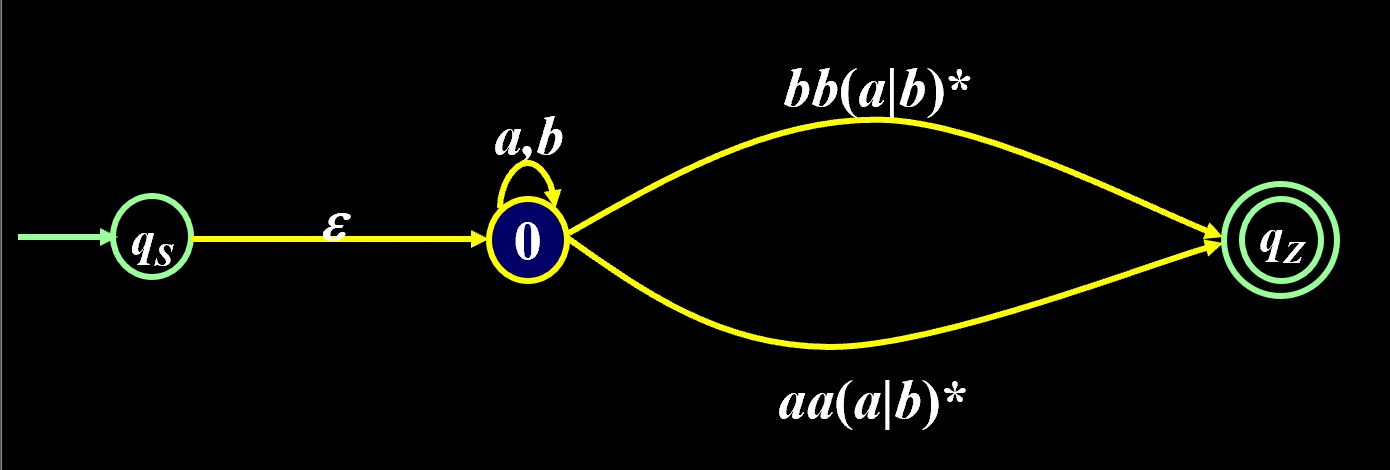
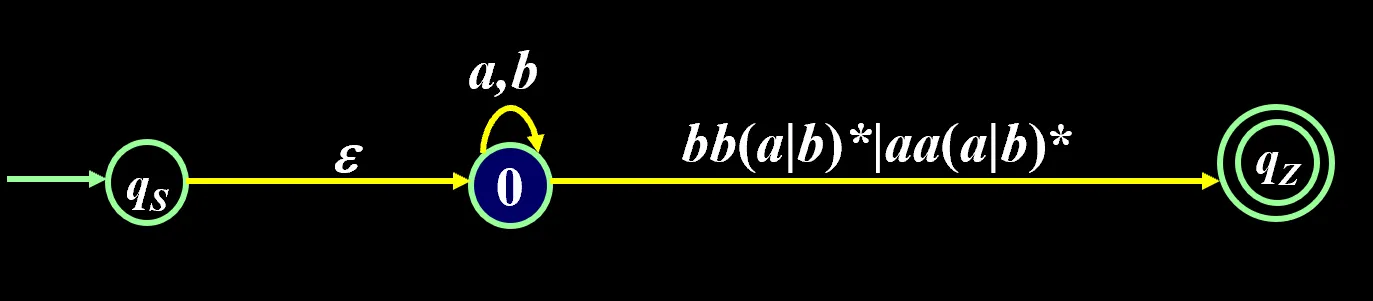

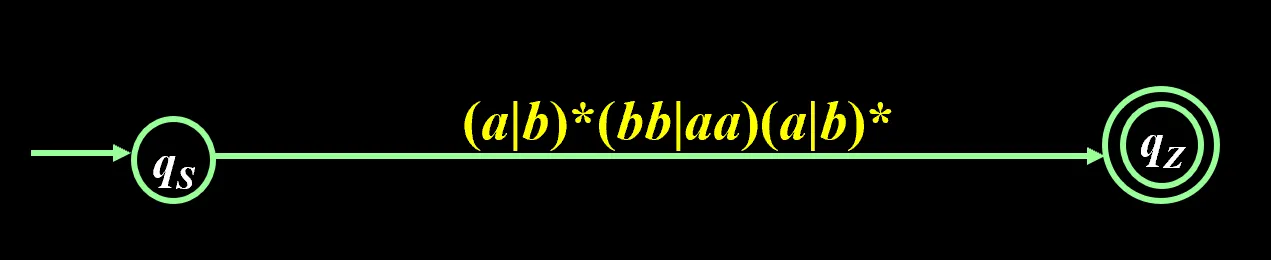
最后这条线上的就是 r
从正规式到 FA#
方法:先从正规式写出 NFA,然后确定化成 DFA,然后最小化
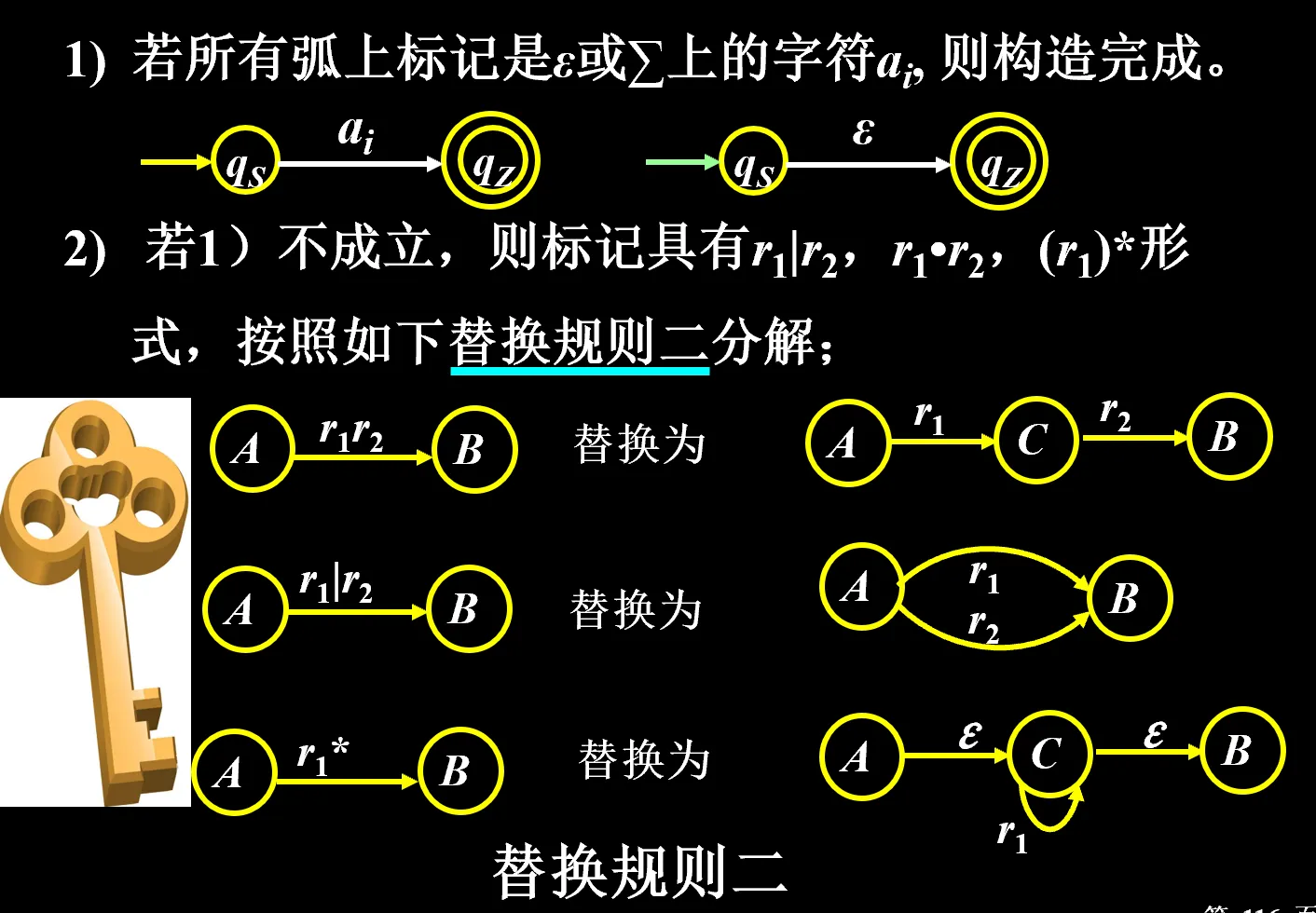
写 NFA:乘法串行、或并行、循环“两ε夹一环”。拆到最后每条边上只能剩下单个字母或者ε
词法分析器的设计与实现#
看 ppt
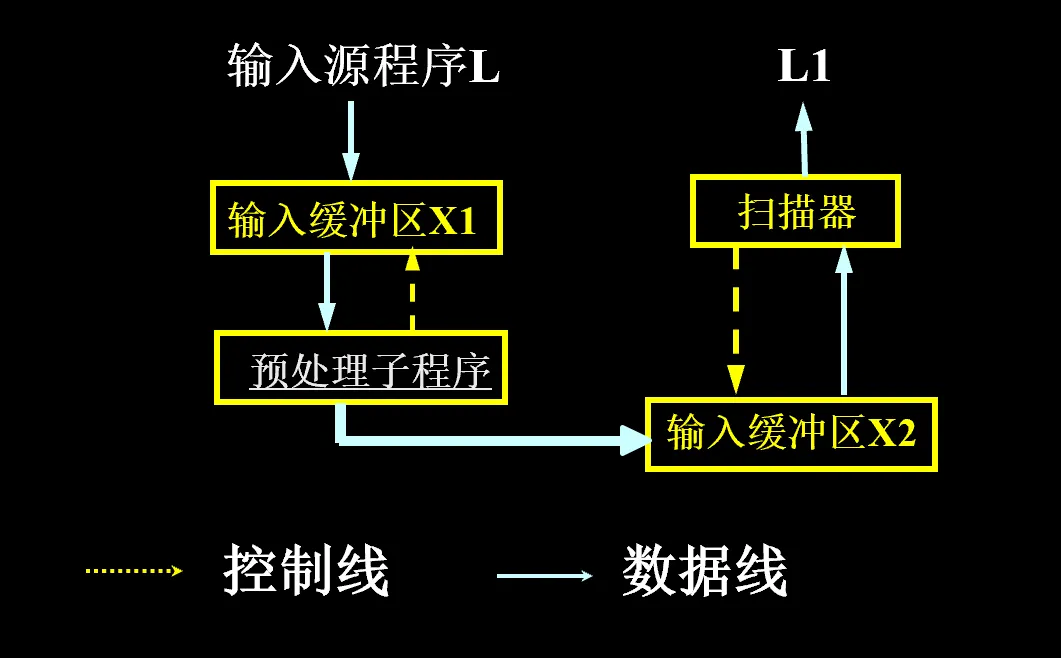
DFA 的激活:数据中心法/程序中心法
数据中心法:将最小 DFA 用一种数据结构 (状态表) 存储,用总控程序控制输入的源程序串在其上运行。
状态表由主表和分表组成
- 主表的每一行:状态 - 地址(当状态为终态时,为子程序入口地址;当状态不是终态时,为分表地址)
- 分表的每一行:当前输入字符 - 转换到的新状态
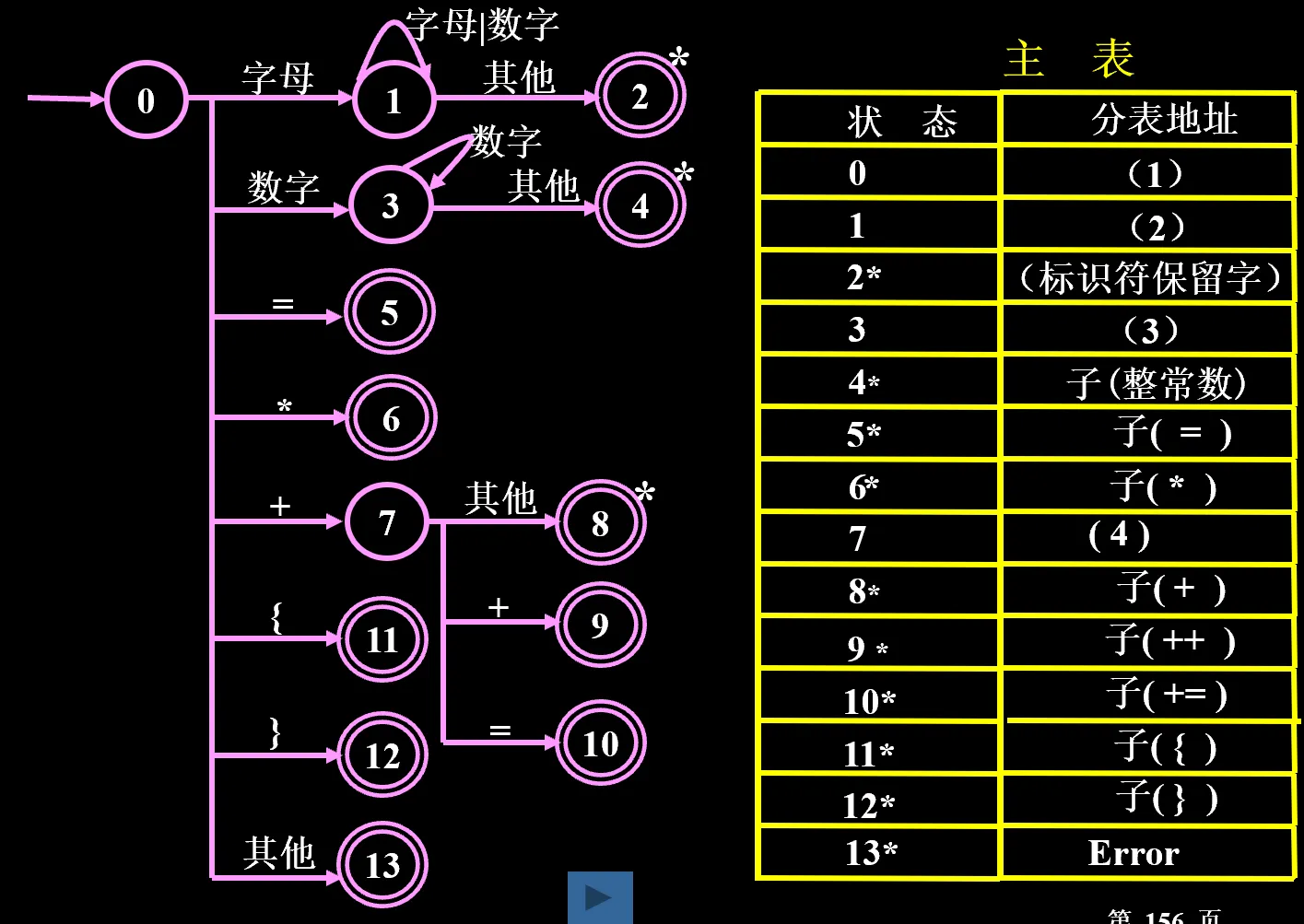
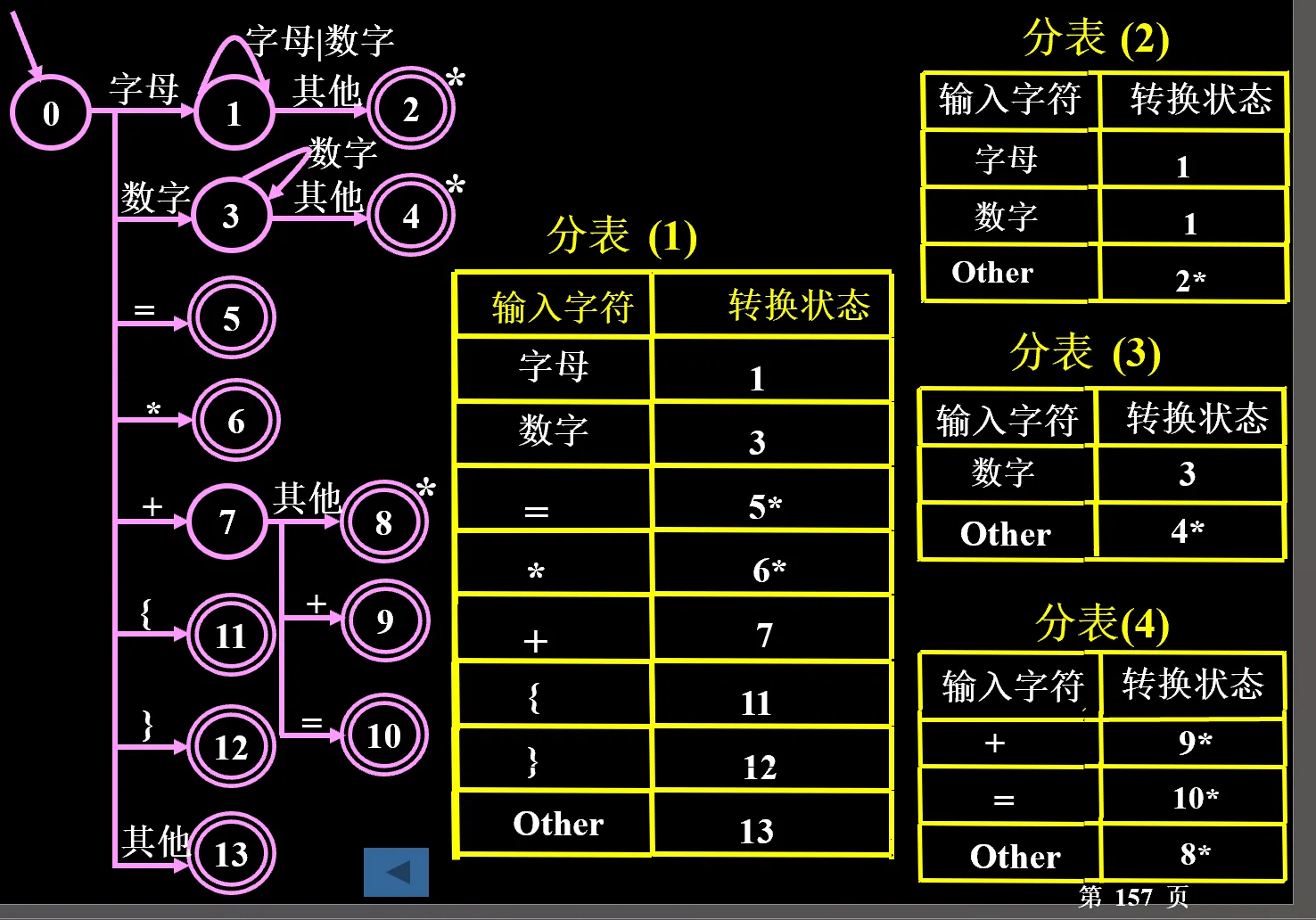
算法:建立状态寄存器 B、字符寄存器 W、字符串寄存器 W’
- 初值设置:B 为初态、W 和 W’ 均为空
- 据 B 查主表
- 如果是分表地址,则读入当前字符到 W,指针前移,组合单词 W’=W’+W,转 (3);
- (如果是子程序入口,则转 (4)
- 据 W 查分表,将 W 对应的状态存入 B,转 ()2)。
- 终态处理:输出单词 (W’) 属性字,转 (1);
程序中心法:直接把 FA 写成 while 循环和 switch 的程序。看 ppt