| 分析 | 说明工具(数学表示的方法) | 识别工具 |
|---|---|---|
| 词法分析 | 正规式 | NFA |
| 语法分析 | 上下文无关文法 | LL、LR |
文法#
文法是一个四元组
非终结符号集
终结符号集
文法的开始符号或识别符号
产生式集
有的时候只写产生式集(下面有例子)
VN VT 合称文法 G 的符号集 V
产生式集:

黑色的就是非终结符,绿色的就是终结符
箭头左边称为左部,是 的元素,且必须要包含 中的一个元素。
右边称为右部/候选式,是 的元素。
开始符号必须至少在某个产生式的左部出现一次。
句子的推导与归约,推导就是左部到右部;归约就是右部到左部
推导:从 S 开始,反复用产生式的右部去替换左部,得到一个由终结符号组成的字符串。例如这个,称为直接推导序列。记作 ,(如果还有 也可以记作 )

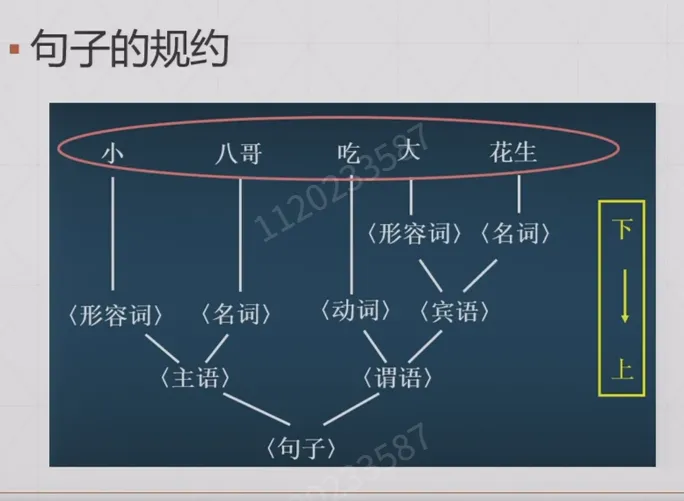
文法 生成的语言 :是所有用 G 可以生成的终结符号串的全体
句型:
句子:
如果推导过程中,总是对句型中的最左边的非终结符进行替换,称为最左推导
如果推导过程中,总是对句型中的最右边的非终结符进行替换,称为最右推导/规范推导。
至于选择哪一个产生式做推导,并不在乎
仅用规范推导得到的句型称为规范句型 。规范推导的逆序为规范归约。
例子:
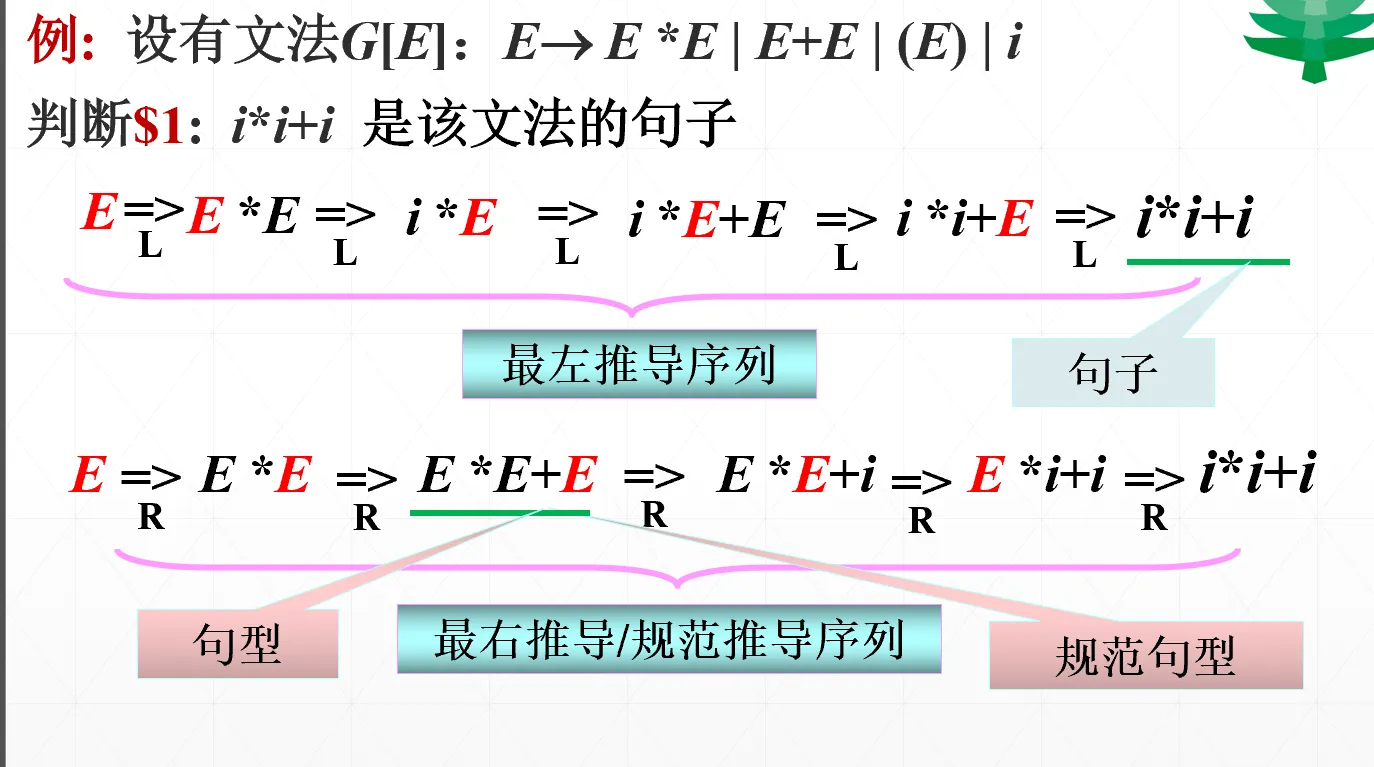
这个文法就只写了产生式集,这里总共四个产生式,E 就是非终结符,i 就是终结符
这还引出了“递归文法”的概念
文法 G 的产生式形如
- 若 则称为直接递归文法,递归的非终结符出现在了产生式的右部
- 若 则称为间接递归文法
- 若 则称为左递归文法(就是说 产生式后部当中,左半部分是递归的)
- 若 则称为右递归文法(就是说 产生式后部当中,右半部分是递归的)
直接/间接 x 左递归/右递归。只要其中一条产生式符合某个递归,整个文法就算这个递归

也是直接右递归
关于间接递归的例子

语言推文法#
必考
ppt p42 to 52
注意 n 是从 0 开始还是从 1 开始
重复式



不等号

倍数处理方式(直接背下来)

解析:第一题,用横线下面那个式子好理解。aTbb 就是先让 b 的个数是 a 的两倍,然后 aTb 就是让 a 和 b 同时增长,这样就能控制在 1 到 2 倍之间。
第二题是一样的道理,aTbbb 就是先让 b 的个数是 a 的三倍。然后不能只通过 aTb 来调整倍数,否则 abb 就凑不出来了,所以要加一个 aTbb
然后还有两个文字描述的例子,也是直接背下来

第一条:添加正负号。这一条一定没法用递归文法,所以单独拎出来
第五条 A:1 3 5 7 9
第四条 B :1-9
第三条 C:0-9
第二条:构造式,无符号奇整数,要么是一位数(A),要么是两位数(BA),要么是三位及以上(BDA),其中 D 是任意 0-9 符号串

解析:记右下角那个写法。类似以前 qee qeo qoo qoe 自动机的那个题,只不过这里 qee 和 qoo 合到一起了
文法的描述方法。
- BNF 表示法(尖括号表示非终结符,就是之前举例子用的)
- EBNF 表示法(增加了大中小括号。花括号表示重复次数,圆括号表示分配公因式,方括号表示可有可无)
- 语法图表示法(一个起始结点和一个终止结点。终结符结点用圆形表示,非终结符结点用方形表示)
EBNF 三个例子

语法图例子
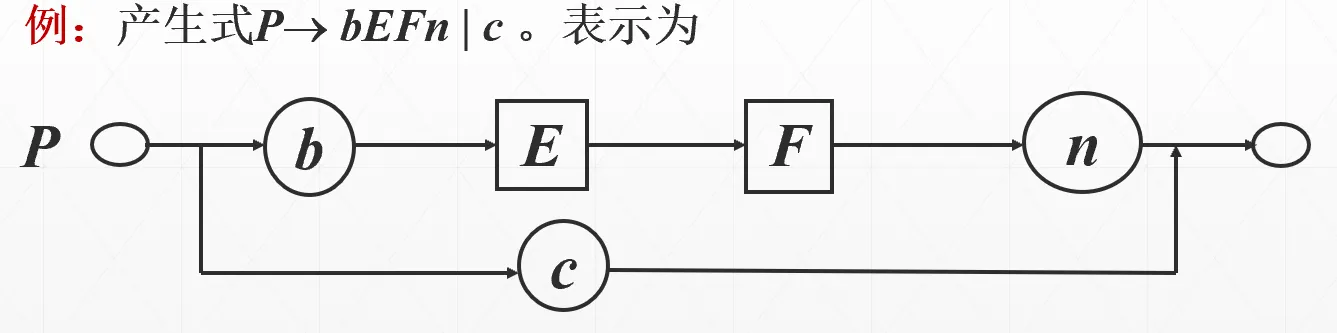
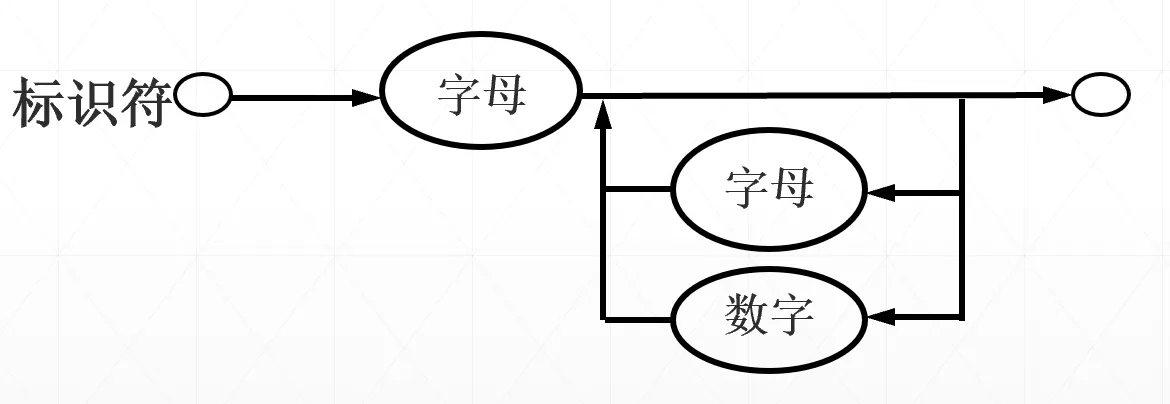
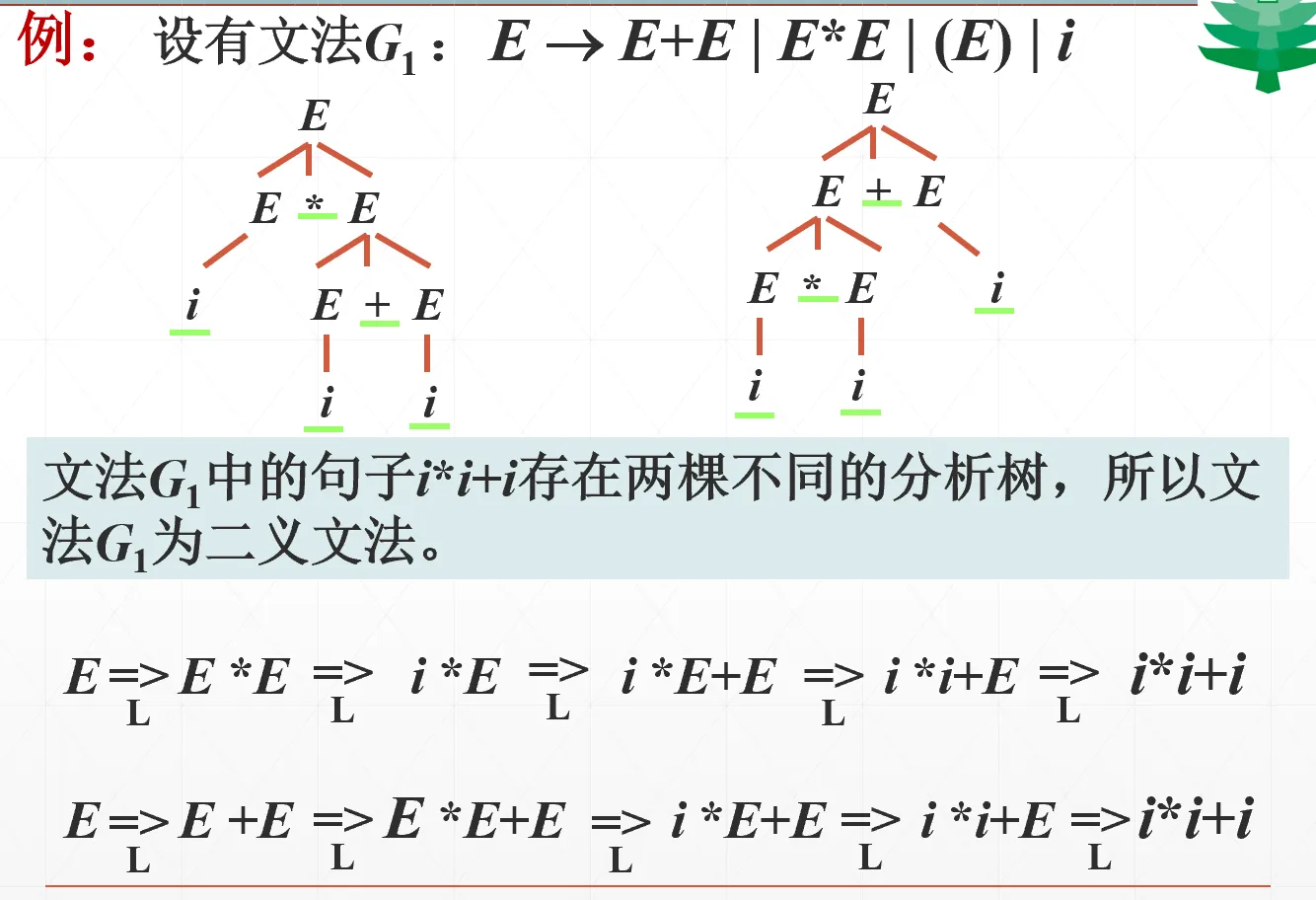
二义性与语法树#
语法树:句子从文法中推导出来的过程中生长出来的树。终结符是叶子
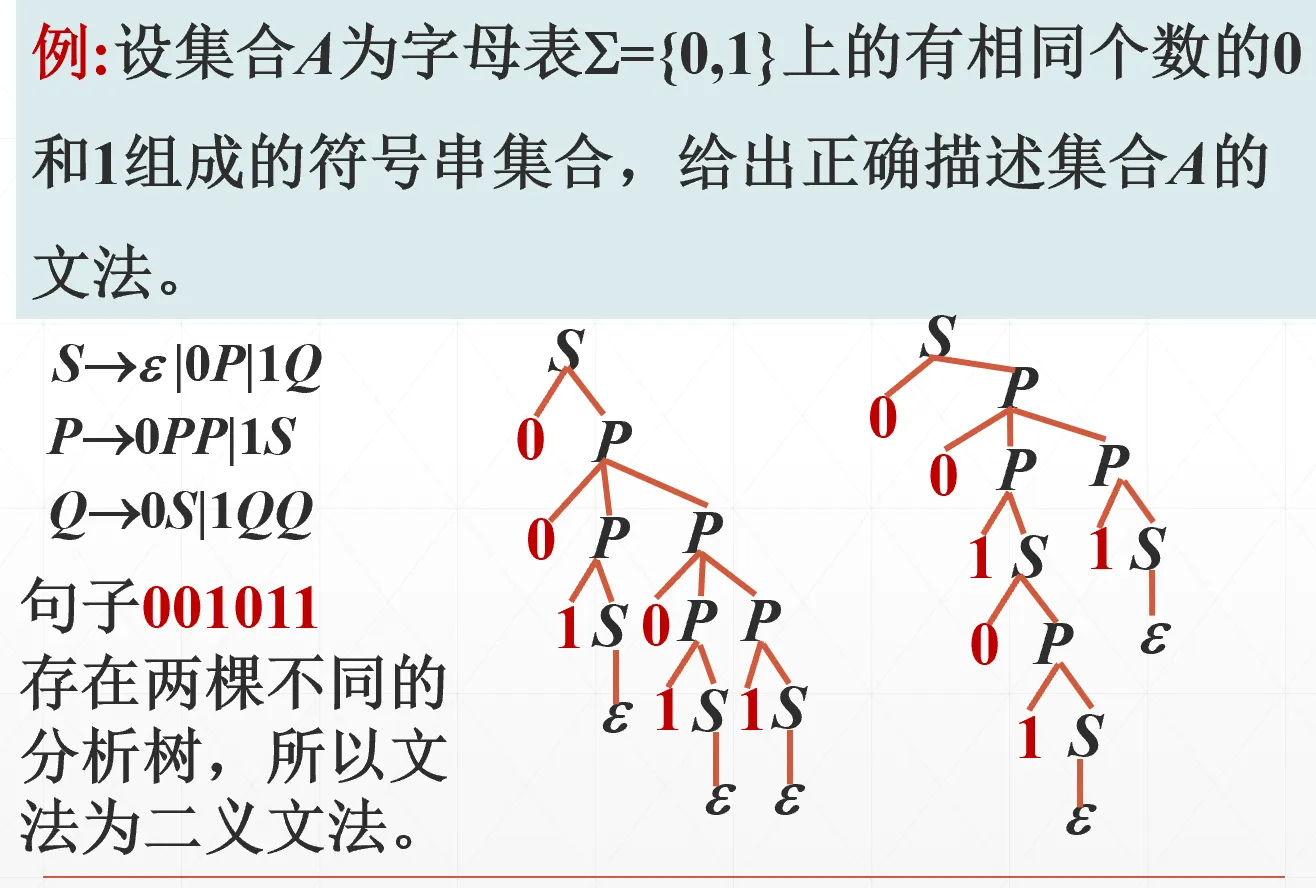
句子二义性:一部文法 G,如果至少存在一个句子或句型,有不只一棵分析树(或最左推导或最右推导),则称该句子或句型是二义性的。
包含有二义性句子(或句型)的文法称为二义文法。否则,该文法是无二义性的。
这个例子:25 是无二义性的句子,只是展开的顺序不一样,最左推导是在第三层先推导数字串,最右推导是在第三层先推导数字

有二义性的例子
二义性消除的方法:在文法中规定优先级、并规定结合规则。优先级越高的越在下面。结合律:只要不是符号两边都是相同的非终结符应该就可以(暂时的理解)。下面这个两例子要背下来

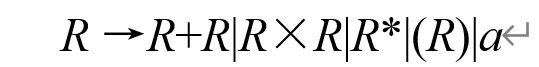
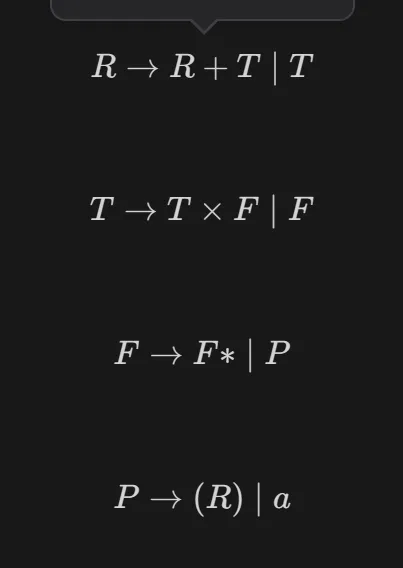
四类文法#
四类文法。k 型文法描述的语言称为 k 型语言 ,k=0 1 2 3。从 0 到 3 限制越来越严,描述能力越来越弱
ppt 中每个类型的文法都给了例子,当作推导的练习(就是文法推描述)
0 型文法( 短语文法 )就是最基本的文法。0 型语言可以用图灵机识别。
1 型文法(上下文有关文法):要求产生式必须满足 ,其中 A 是非终结符, 无所谓。也就是说每条产生式必须有上下文,可以只有上文,也可以只有下文。1 型语言可由线性有界自动机来识别
2 型文法(上下文无关文法):要求产生式必须满足 ,其中 A 是非终结符, 无所谓。也就是说每条产生式都不能有上下文。2 型语言可由非确定的下推自动机来识别
3 型文法(线性文法、正则文法)。要求产生式必须满足以下条件的其中一个,要么都是左线性,要么都是右线性,不能混在一起
- 左线性文法:(左边非终结)
- 右线性文法:(右边非终结。实在分不清就写 3 型好了)
其中 是非终结符, 是终结符构成的串。3 型语言可由 DFA 来识别,画 FA 的方法如下(注意只是 FA 因为还有空串,要等价成 DFA)
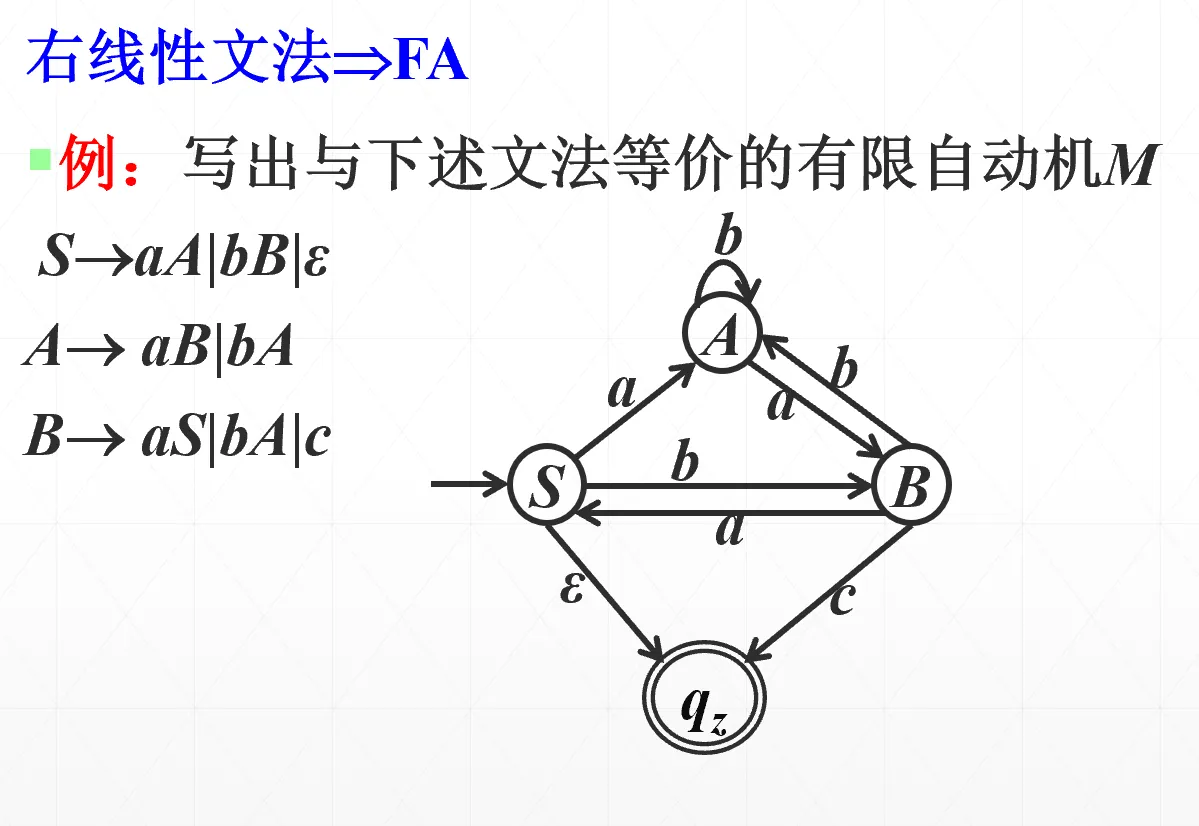
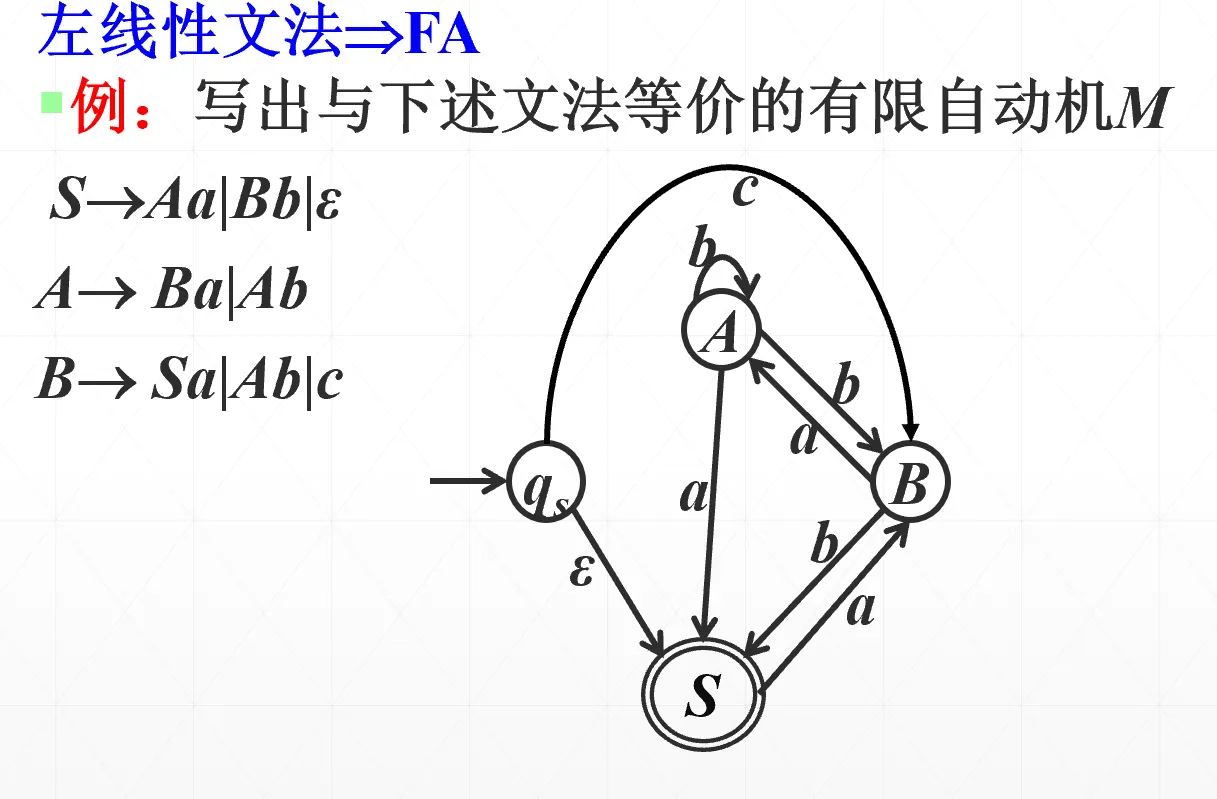
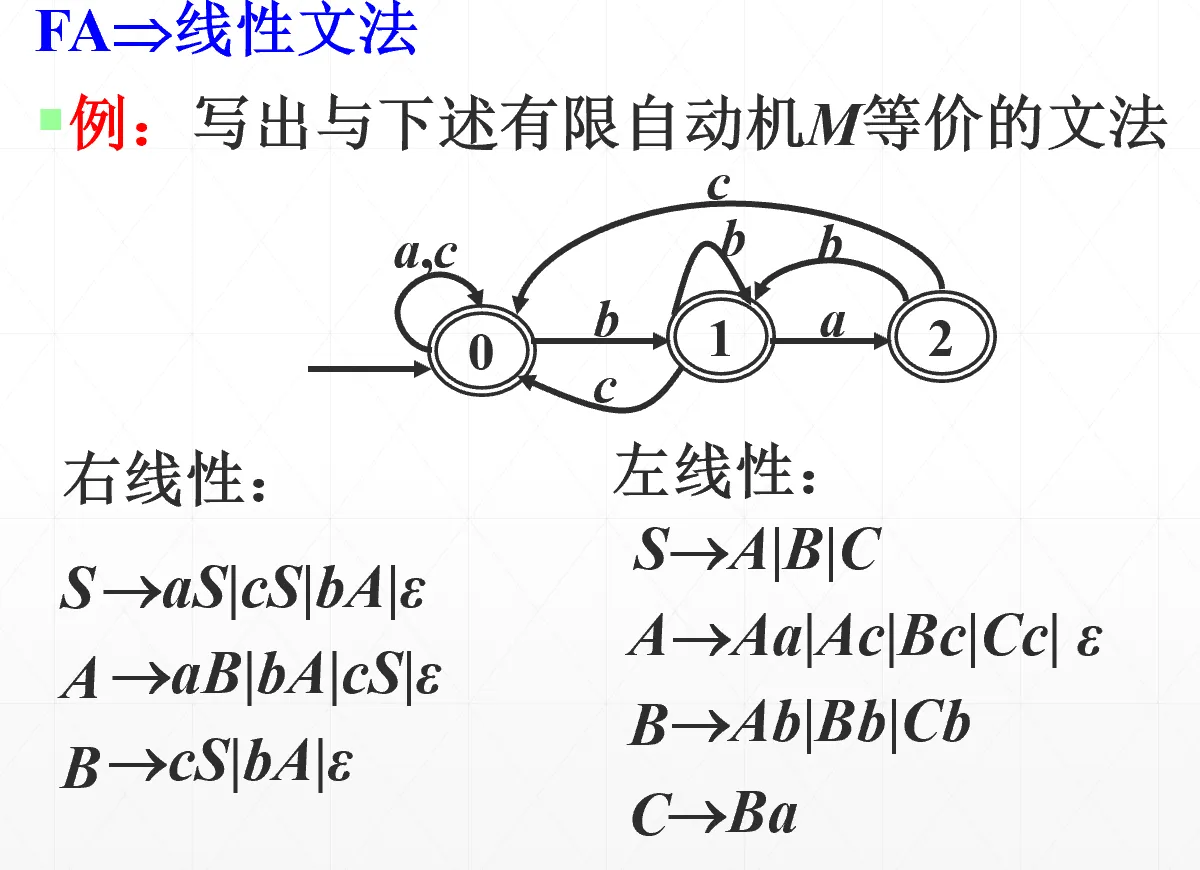
语法分析方法#
给出一个算法,自动判断属性字流是否属于某个文法
自顶向下:就是从开始符号 S 开始,用产生式的右部替换非终结符,逐步推导出句子。重点在于如何选择合适的产生式
自底向上:就是从句子中寻找与产生式匹配的子串,并用产生式的左部替换之(称为归约),直到归约到开始符号 S。重点在于如何选择可归约串
自上而下分析#
不确定的自上而下分析法#
下面的所有讨论都是基于最左推导
自上而下分析的本质 是试探,尝试使用不同的产生式谋求匹配输入串,带回溯,算法效率低开销大。
而且如果有左递归,当分析器尝试匹配非终结符 时,它会根据产生式 再次尝试匹配 。这个过程发生在尝试消耗任何输入字符之前,这会使分析树无休止的延伸,陷入死循环。
右递归没事。因为分析器会先处理左侧的符号 ,如果 是终结符(或者能推导出终结符的非终结符),分析器会先匹配并消耗输入字符串中的字符。只有在当前输入匹配成功后,分析器才会递归地调用自己处理剩下的部分。由于输入字符串的长度是有限的,每递归一次就消耗一些字符,最终会因输入耗尽或匹配到终止情况而停止。
- 例子: 。对于输入
00a,它会先读两个0,最后读a结束,不会死循环。
这就是“不确定”的两个原因:
- 假匹配
- 左递归
解决方法:消除左递归 / 提取左公因子
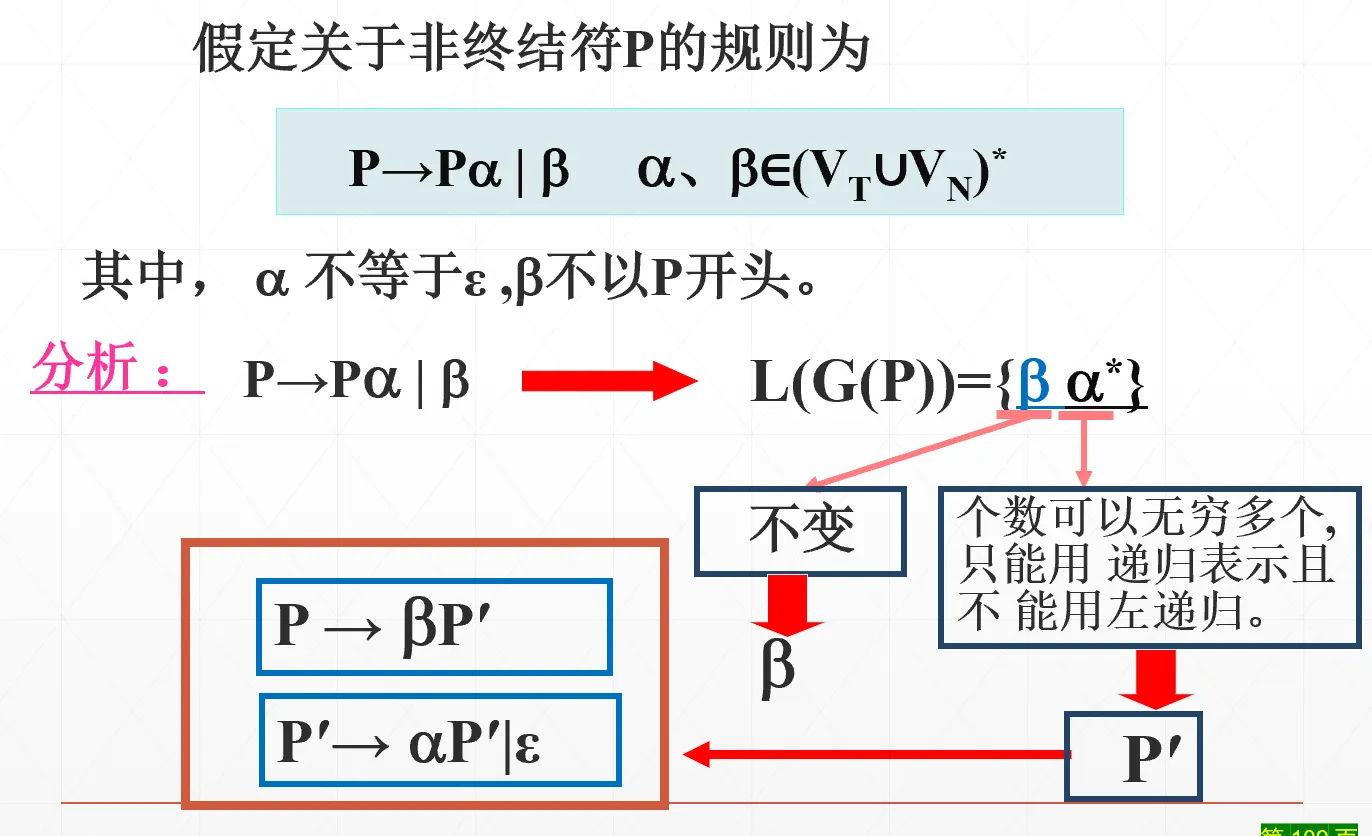
消除左递归#
对于直接左递归:引入新的非终结符,转换为右递归。母公式,直接背下来:

例题:

加乘表达式例题
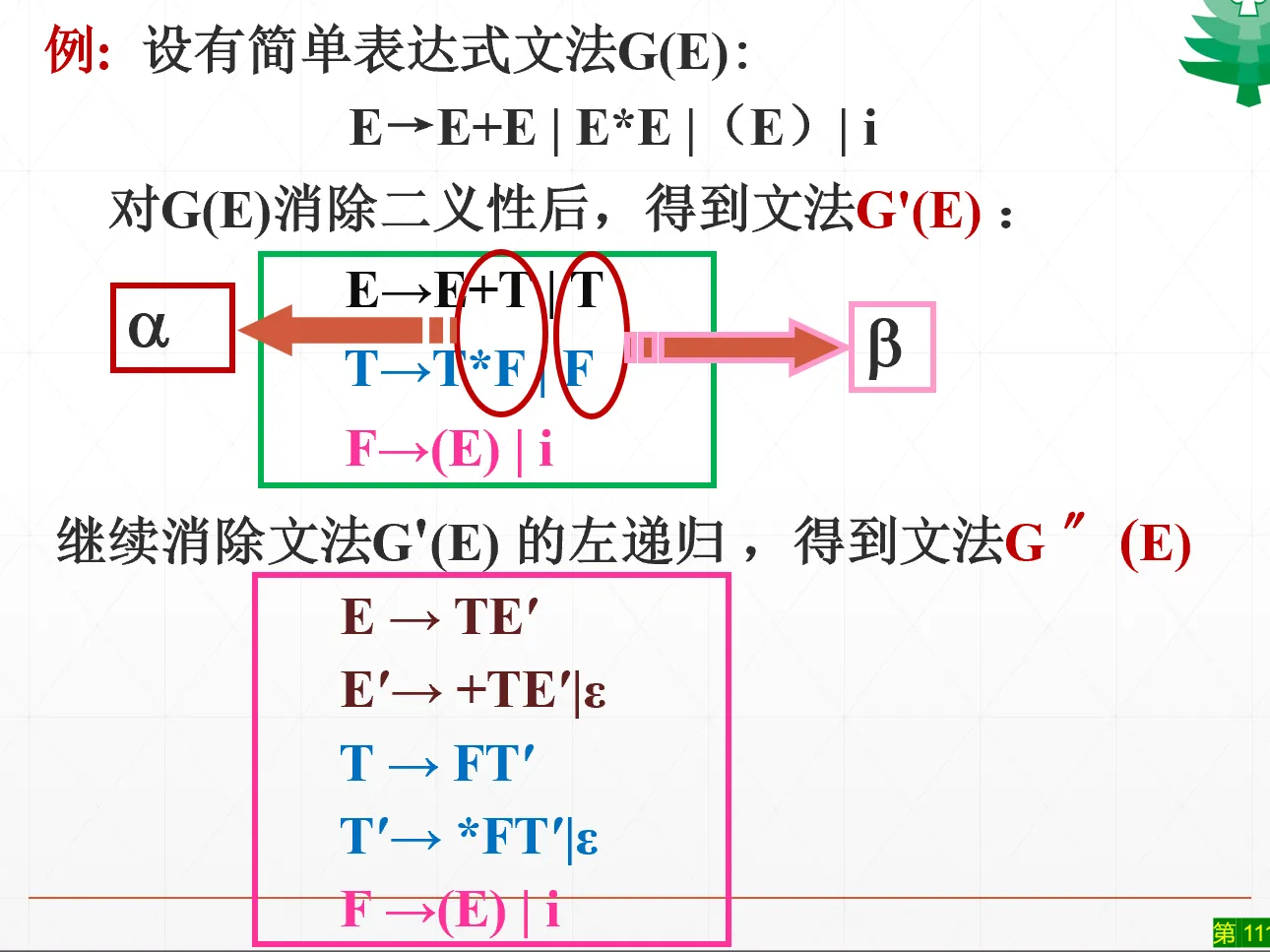
对于间接左递归:先改写成直接左递归文法,然后套用刚才的
Algorithm:消除左递归算法。要求:不含回路 ;不含以 ε 为右部的产生式

先规定一个非终结符顺序。然后按顺序一个一个处理非终结符的产生式。如果出现了“前面的非终结符”的左递归,则用右部替换掉,重复操作直到不出现“以前面的非终结符开头”的产生式。然后用母公式消除直接左递归。例子

消除假匹配#
对 (也即由终结符或非终结符组成的序列),定义它的 FIRST 集:集合里面都是终结符,并且这个终结符是“ 经过若干步推导得到的句子或句型 的第一个字符(不要求一定能从 S 推导出来,这一点和后面 FOLLOW 集不一样)”。如果能推导出 ε,那么 ε 也要加入 FIRST 集
曰:如果文法满足以下条件,则一定不带回溯(反过来不成立,也即充分不必要):对于 ,每个候选式 均不能推导出 ε,且这些 的 FIRST 集两两不相交。
两两不相交很好理解,因为第一个字符决定了你要用哪一个候选式;不能推导出 ε,是因为一旦能够推出 ε,就说明这个非终结符可以被跳过而不消耗输入流的任何字符,于是就要看下一个非终结符,相当于又调用了一个子程序,也即涉及到回溯
如何计算 FIRST 集(一定要反复检查,后面很多东西依赖这个 FIRST 集)
- 单个符号的 FIRST 集:如果 X 是终结符,则 FIRST(X)={X};如果 X 是非终结符,则 FIRST(X) 是所有候选式的 FIRST 集的并集
- 里的串的 FIRST 集:Algorithm 如图。第一步中 FIRST(X1) 要去掉 ε,因为还有 X2 的存在,不能保证 α 能推出纯 ε。第二步的循环,就是要考虑 FIRST(X1) 能推导出 ε 的情形,这时候 X1 被跳过,那么 X2 的 FIRST 就变成了 α 的 FIRST。如果做完之后还能推导出 ε,才说明 α 能推出纯空,此时 ε 才能加入 FIRST(α)。如果中间出现某个 Xi,它的 FIRST 集里头没有 ε,就可以停了

所以,如果候选式的 FIRST 集存在交集,消除假匹配的方式:提取左公因子,提完就必然没有交集了

注意,消除假匹配不意味着不用回溯,因为还有ε的问题
LL(1) 分析法#
判断一个字符串是否属于该文法。分析过程:维护一个栈(分析栈)。指针指向待处理的字符、选择合适的候选式倒序入栈、对栈顶元素反复推导、直到产生这个字符,然后这个字符出栈、指针右移。直到最后栈空,就算属于这个文法
选哪一个候选式,就是 LL(1) 分析法要解决的
命名的由来:
- L:扫描顺序:自左向右扫描
- L:分析模式:最左推导
- (1):在分析中最多向前看 1 个输入字符
分析表:一行是一个非终结符、一列是一个终结符,表里头的元素称为预测分析函数。预测分析函数要么为空白,要么为这个非终结符的一条产生式(后面会讲到“一条”的作用,见 LL(1) 文法)
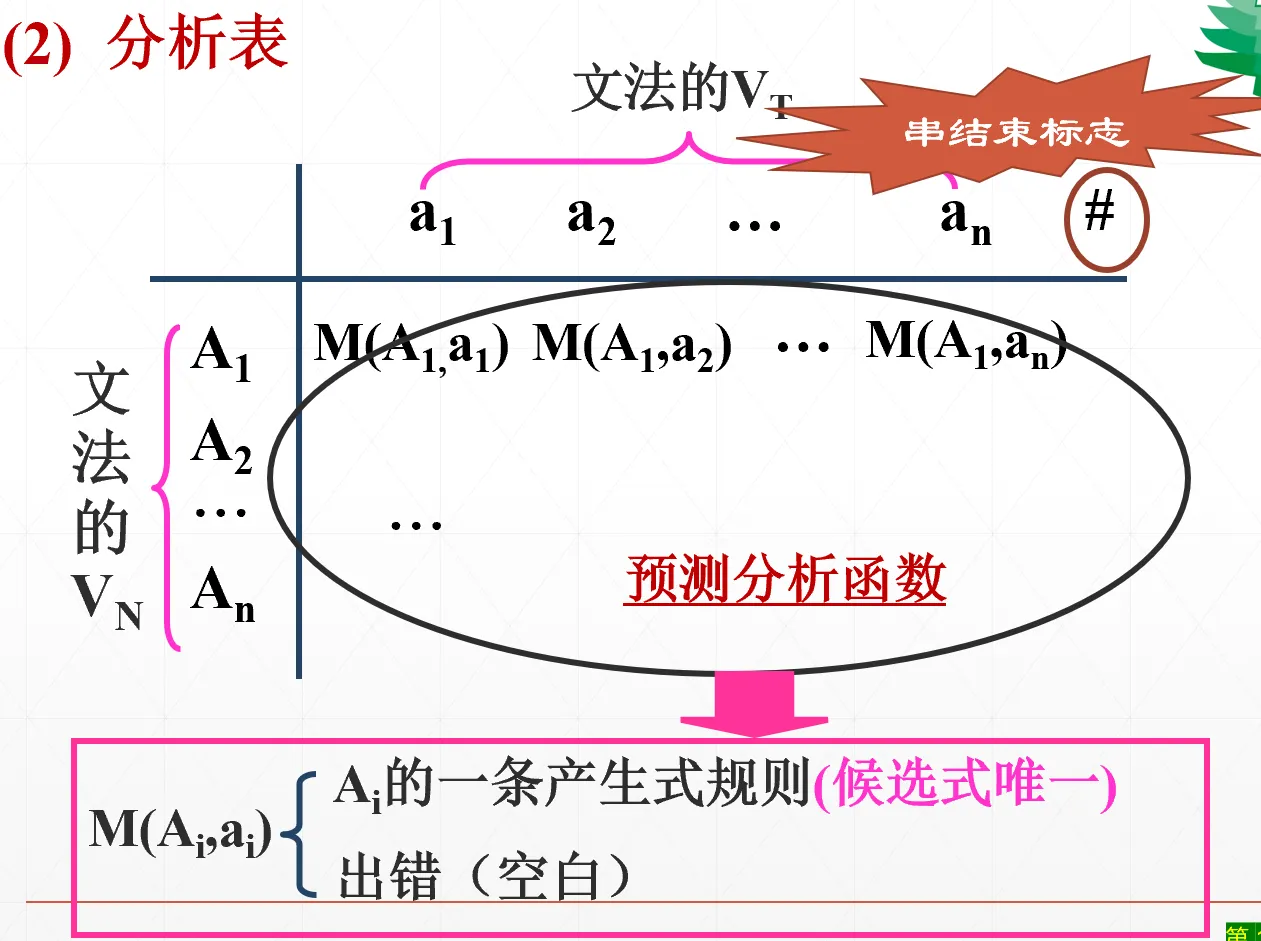
先学会用这个表格,至于这个表格怎么来的 先不管
如果栈顶是终结符、且为字符串结束符,则分析成功
如果栈顶是终结符、且与指针指向的字符相等、且不是字符串结束符,则出栈、指针右移
如果栈顶是终结符、且与指针指向的字符不相等,则不属于文法
如果栈顶是非终结符 、当前指针指向的字符为 则查看分析表的
如果 为一个产生式,则出栈、然后把候选式倒序入栈
如果 为空白,则不属于文法
例子:语法分析 ppt 161-162
现在来看分析表是怎么来的。
对于一个非终结符 ,定义它的 FOLLOW 集:集合里面都是终结符,并且这个终结符是“在文法的所有句型/句子中紧跟在 后面的那个字符”。如果 ,那么 # 也要加入 FOLLOW 集。既然是文法的句型,那说明必须要能从 S 推导出来。这个和 FIRST 集不一样
如何计算 FOLLOW 集:Algorithm。按照下面的规则 遍历所有含 A 的候选式,往 FOLLOW(A) 当中添加元素:
- 如果 是开始符号,则加入
# - 对于 在候选式末尾的情况,则加入左部的 FOLLOW 集
- 对 不在候选式末尾的情况,则看后面整个串的 FIRST 集,如果含有 ε 则加入左部的 FOLLOW 集,如果含有 非ε 则加入“FIRST 集扣掉ε”
- 一路带入。直到 FOLLOW(A) 的表达式当中,除了 FOLLOW(A) 之外没有其他 FOLLOW 集,这时候把 FOLLOW(A) 划掉,剩下的就是真正的 FOLLOW(A)
Algorithm:写分析表的方法
对于分析表的某一行 ,记 。计算每一个 的 FIRST 集:
- 若存在 使得 FIRST ,则
- 若存在 使得 FIRST ,则对 FOLLOW(A) 中的所有元素 ,都有
- 否则置空
(也就是说:如果这一行的 A 的候选式中没有一个 FIRST 含 ε 的,就不用算 FOLLOW(A) 了)
写一整个表的方法:首先先计算每一个候选式的 FIRST 集。然后一行一行填表:
- 对于 FIRST 集不含 ε 的候选式,则对 FIRST 集中出现的每一个字符,填入这个候选式。其他置空
- 对于 FIRST 集含 ε 的候选式,则对 FIRST 集中出现的每一个非ε字符,填入这个候选式;然后对左部 FOLLOW 集中的每一个字符,也填入这个候选式。其他置空
例子:加乘表达式的分析表
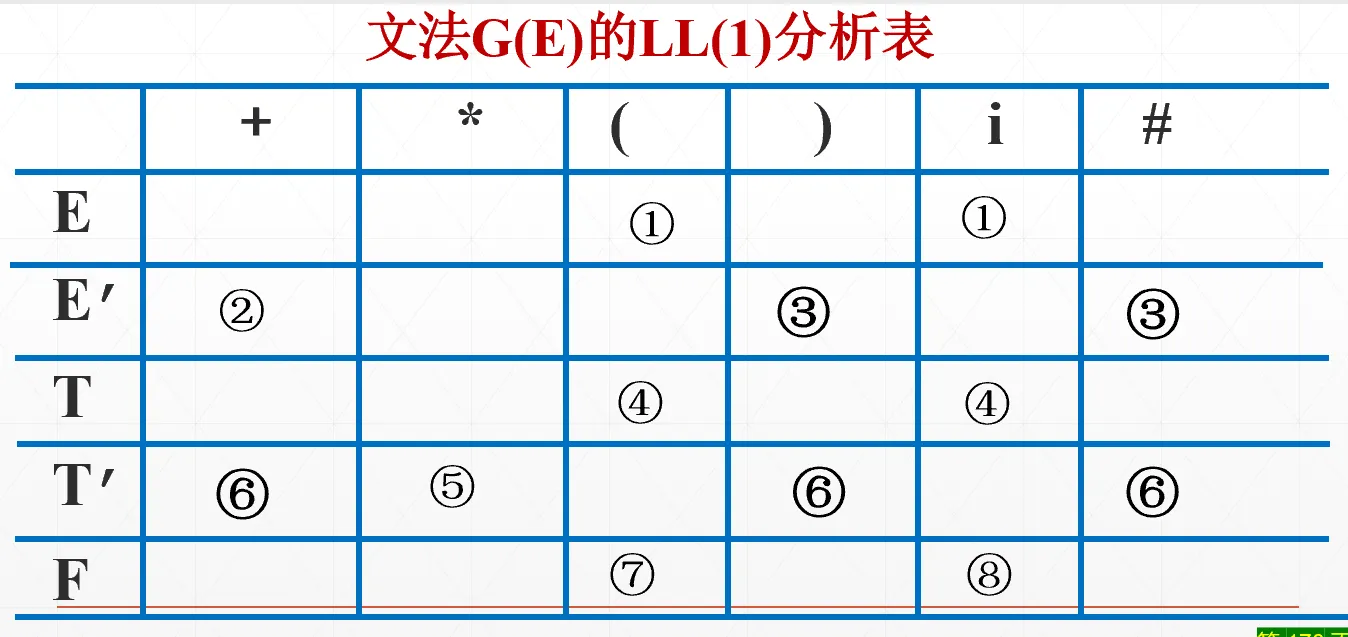
定义 LL(1) 文法:可以用 LL(1) 分析法的文法,也就是“分析表不存在多重入口”。
- LL(1) 文法一定没有二义性
- 左递归文法一定是 非 LL(1) 文法
- 不存在这样的算法,它能判定上下文无关语言能否由 LL(1) 文法产生(语言推文法本来就没有算法,所以才那么难)
一个文法是 LL(1) 文法的充要条件(理论上要求非左递归、无左公因子、无二义性,但其实直接看写出分析表就行了,也就是看下面这个过程):
- 对于每一个产生式,其候选式的 FIRST 集两两不相交
- 且,对于每一个产生式,如果某个候选式能推出 ε,则左部的 FOLLOW 集与其他候选式的 FIRST 集也两两不相交
将非 LL(1) 文法转化为 LL(1) 文法:
- 消除左递归
- 提取左公因,这个可以消除候选式 FIRST 集有交集的情况
- 产生式代入,这个可以消除候选式 FIRST 集和左边的 FOLLOW 集有交集的情况
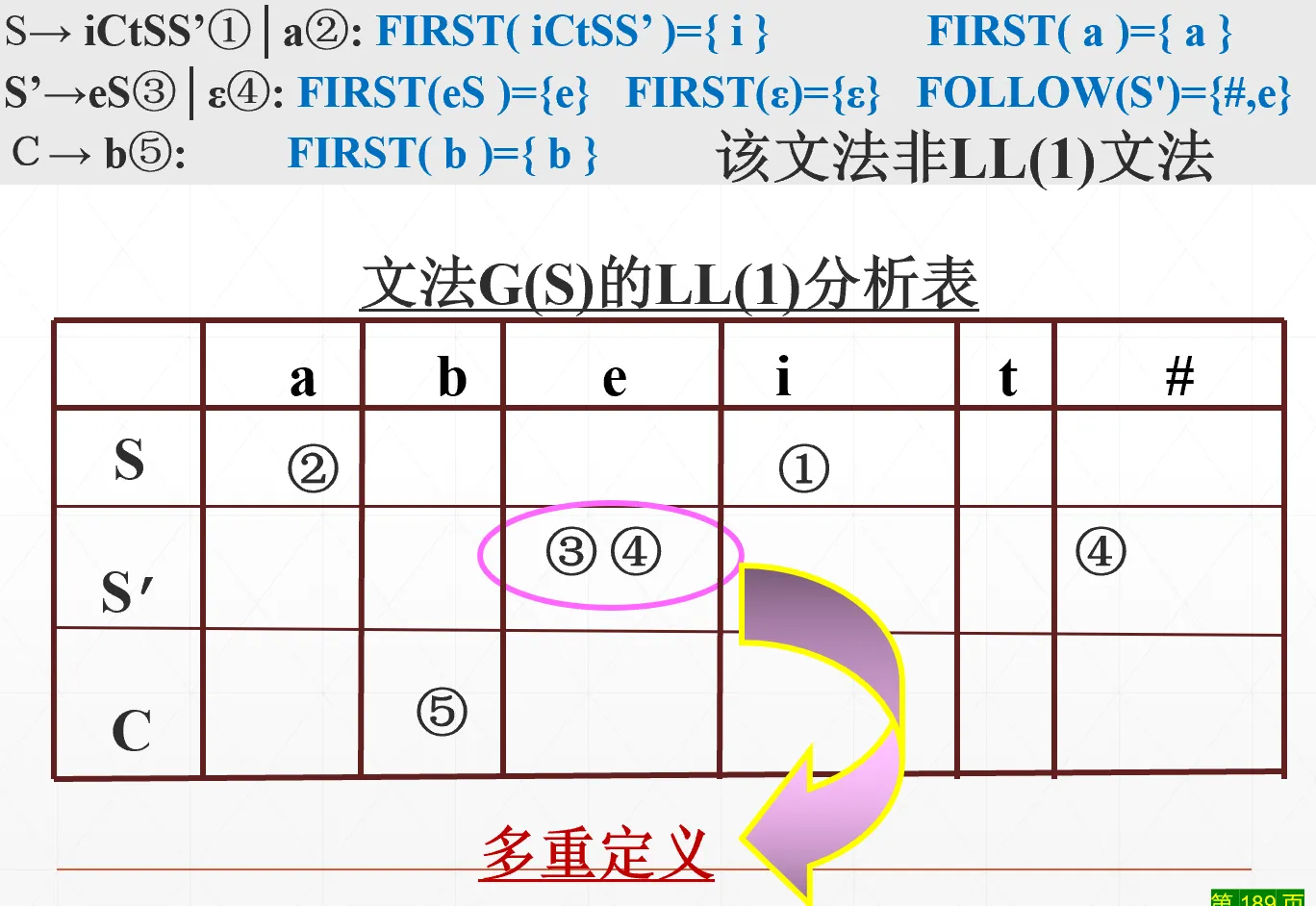
例子:if else 语句的文法

LL(1) 分析器 与 递归下降分析器#
对比词法分析里头:有数据中心法和程序中心法,数据中心法就是查表,程序中心法就是直接写成代码
L L(1) 分析法 - 对应数据中心法,因为我们有 LL(1) 分析表、维护一个分析栈
递归下降分析法 - 对应程序中心法。直接把分析过程写成 if else 语句的程序。
从分析表构造分析程序的过程:不考
使用递归下降分析法的过程:看 ppt p203
自下而上分析#
回顾:自下而上分析,就是从句子中寻找与产生式匹配的子串,并用产生式的左部替换之(称为归约),直到归约到开始符号 S。
所以关键就是:如何确定可归约的串(归约条件)、如何归约(归约原则)
总原则:移进 - 归约#
就是说,每一个步骤,要么把待分析串的符号“移进”分析栈里头,要么利用某个产生式 把分析栈归约成左部。至于什么时候移进什么时候归约、怎么归约,后面再说
例子
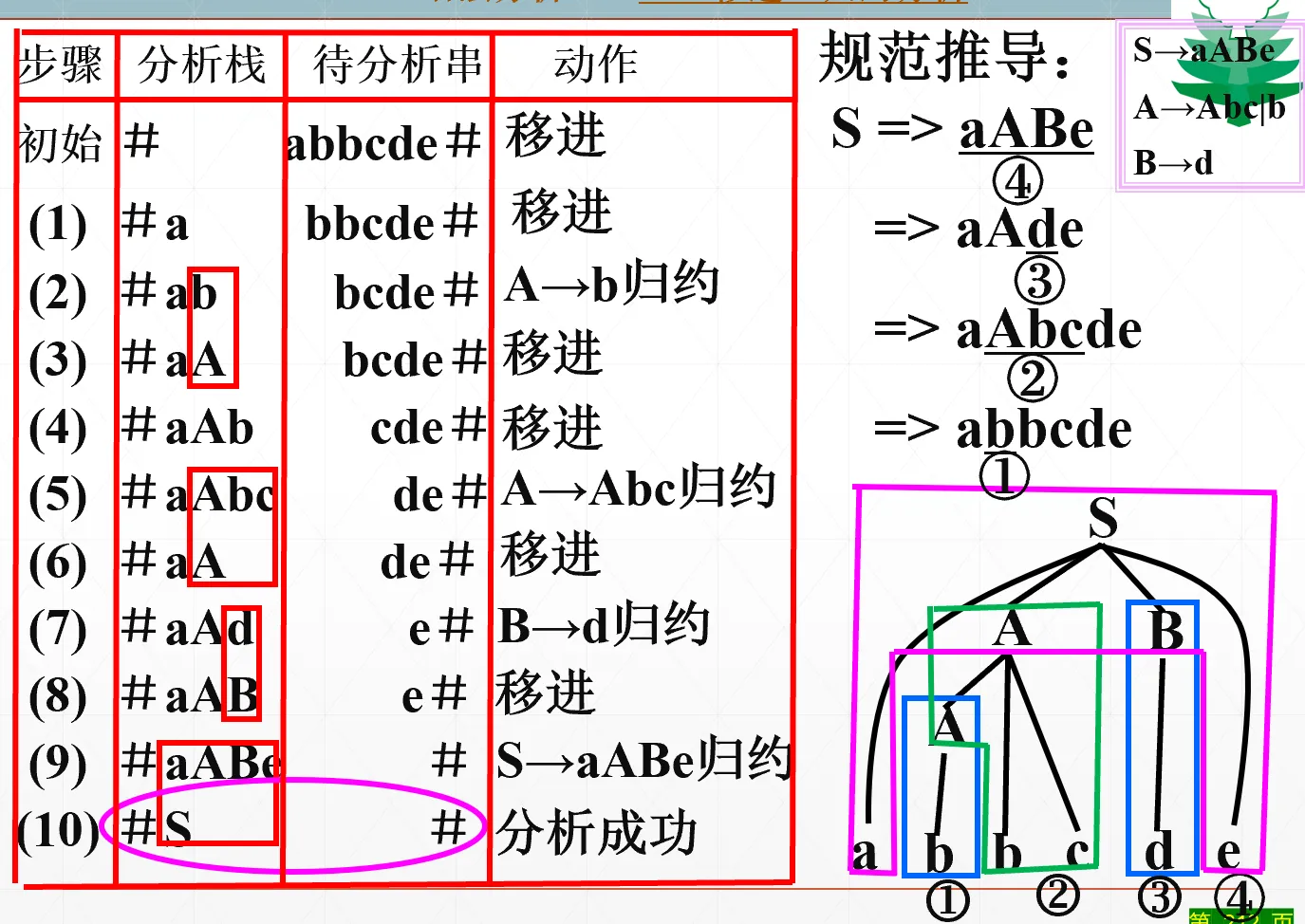
可以看出,移进归约的过程实际上就是最右推导 (规范推导) 的逆过程
短语、直接短语、句柄
- 短语: 是句型 相对于 的短语,当且仅当 能够生成 且 。(也即,对于句型 的分析树当中,存在一个子树,根节点为 ,叶节点为 )。理解上:一个句子里头 suck your dick 这三个词可以被归约为一个动词,于是这就是一个动词短语(相对于“动词”这个非终结符的短语)
- 直接短语:如果这个短语 是 一步推导出来的
- 句柄:句型当中最左边的那个直接短语,称为这个句型的句柄。直接短语一定是不交叠的。
判断句型的直接短语和句柄的方法:构造句型对应的语法树(最右推导)
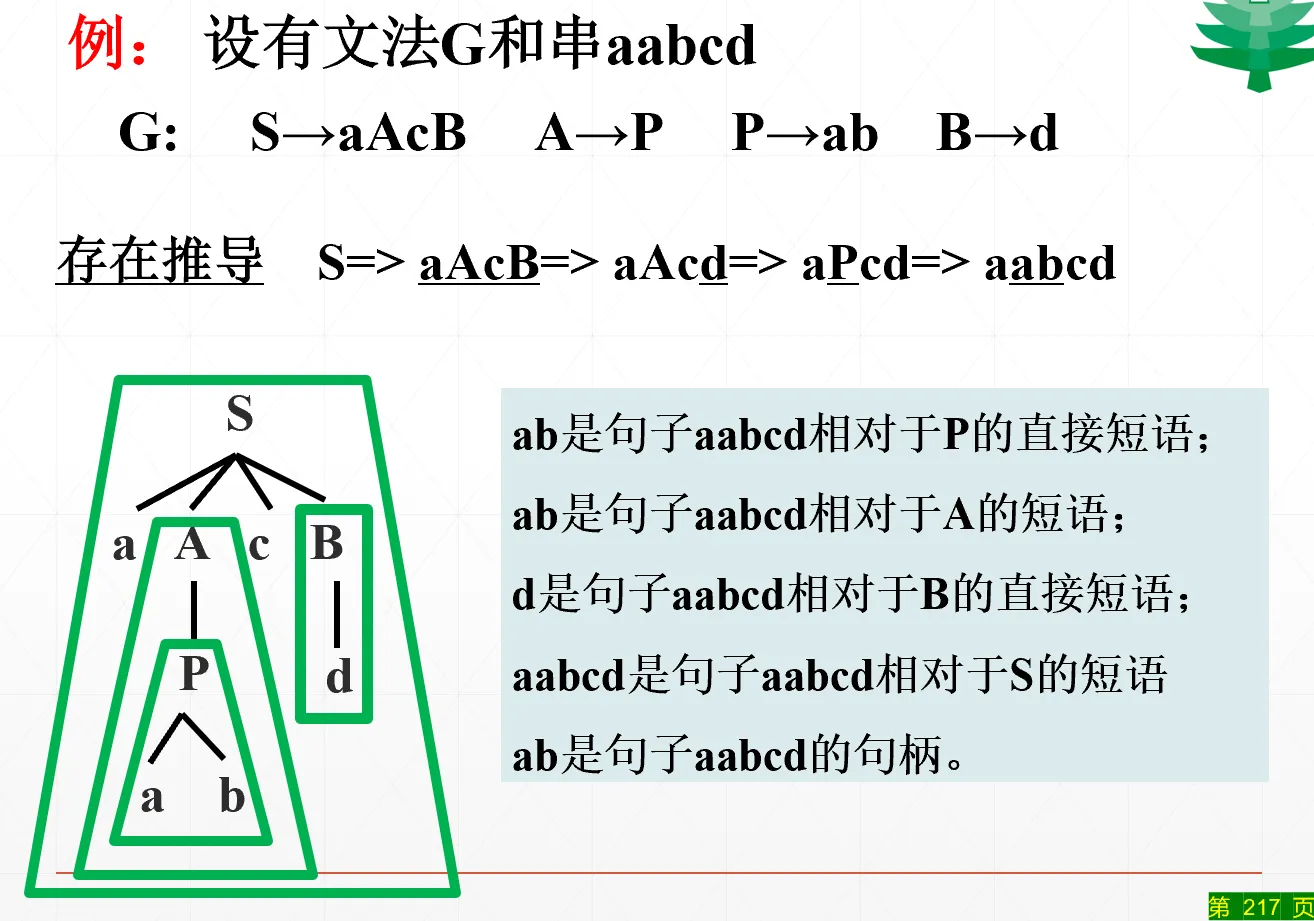
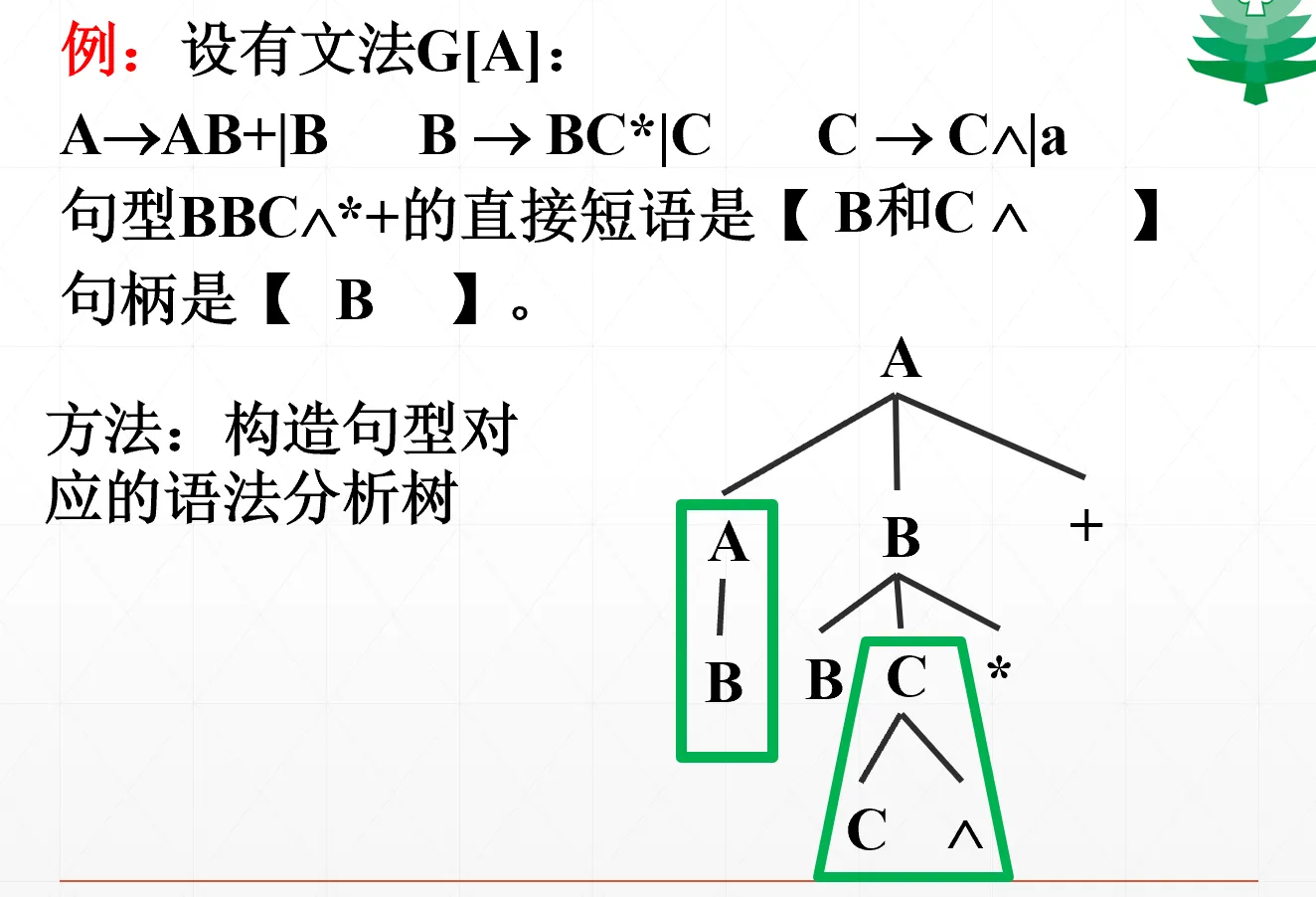
在规范句型的规范推导序列中,最后一步使用的产生式的右部就是这个句型的句柄。序列中的每一步都是句柄
所以移进归约的本质就是“砍句柄”,每一次砍掉一个句柄,砍到最后只剩开始符号就说明分析成功
LR 分析法#
- L:扫描顺序:自左向右扫描
- R:分析模式:最右推导
维护两个栈,一个符号栈,一个状态栈
- 状态栈:记录仅分析过程中每一步的“历史”和“展望”信息
- 符号栈:移进和归约的符号。一般来说终结符是移进产生的、非终结符是归约产生的
LR 分析表
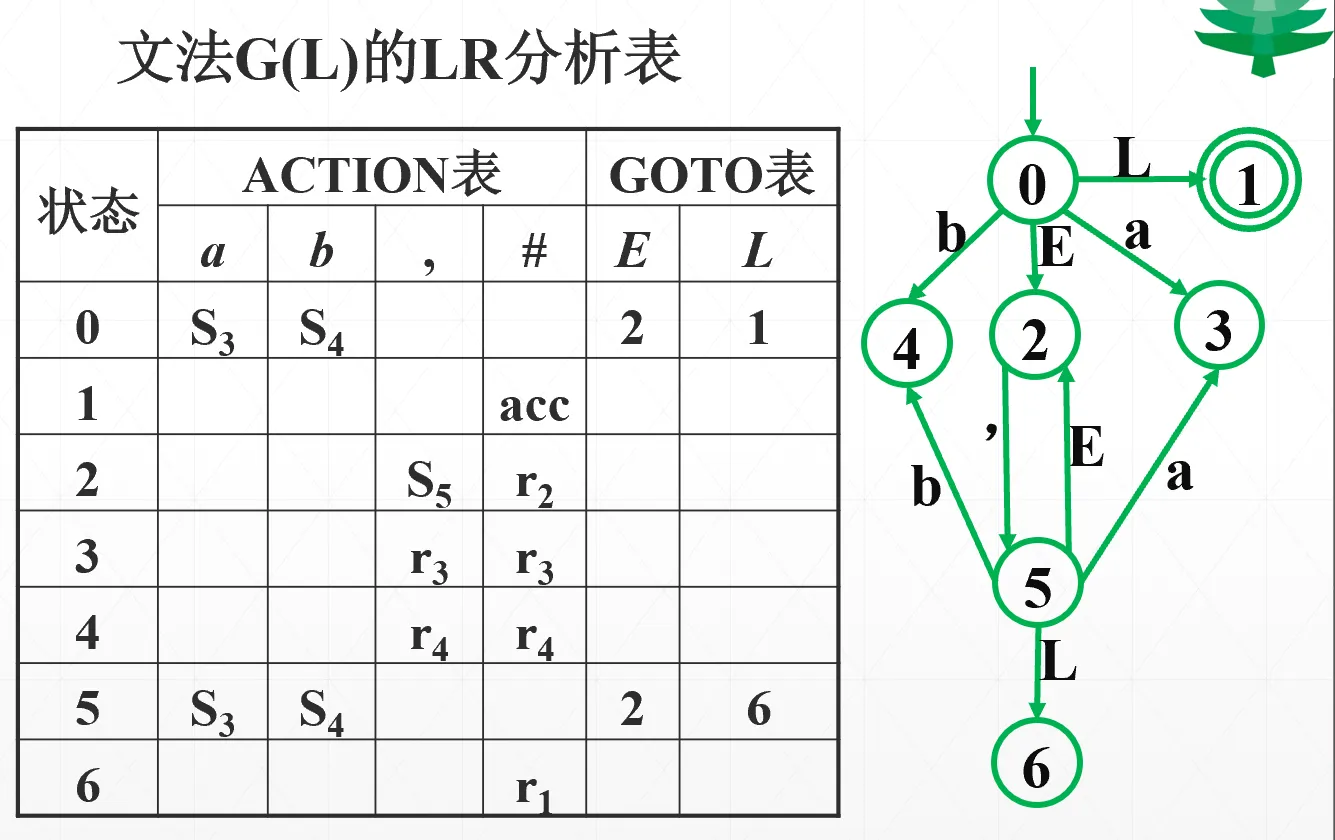
分为两个表。每一行是一个状态。分为两个表
- action 表是遇到终结符/串尾符时候的情况。 表示“将该终结符移进符号栈,并把状态 压入状态栈,指针右移”。 表示“根据第 条产生式的右部,将符号栈和状态栈的对应项全部出栈,然后把左部压入符号栈”;这时候你会注意到,状态栈相比符号栈少了一个状态,这就是 goto 表的作用:
- goto 表是遇到非终结符时候的情况。 表示把状态 压入状态栈
- acc 是 accept 的意思,空白的就是 error
分析时,初始状态为:状态栈仅 ,符号栈仅 ,然后按照 LR 分析表分析。
总控程序如下

先会使用 LR 分析表。至于这个表是怎么来的:我们有四个分析法。分析过程都与 LR 分析法是一样的,区别在于分析表的构造方式不同
LR(0) 分析#
定义:活前缀:规范句型的所有前缀中,不包含句柄右侧的 前缀,称为该句型的活前缀。当恰好包住句柄的时候,称为可归前缀
理解:在移进归约的过程中,符号栈里的东西要么被某条产生式归约,要么是在等待归约;如果在等待,那么相当于栈顶有一个“自由基”,正在等句柄里头的符号压进来然后归约成左部;如果此时进来的是句柄之后的符号,压进栈之后就破坏掉了当前栈顶的“活性”。
LR(0) 分析法。
方法:在每一条产生式的右部的任何位置加一个圆点,构成的每个产生式称为一个 LR(0) 项目(如果是 A→ε 则项目为 A→·)。如果右部长度为 n 则有 n+1 个位置可以打点。特别地,开始符号的两侧也要打点。这通过引入一个新的开始符号 指向原本的开始符号 、以引入一个新的产生式 的方式解决(这一步称为拓广文法)
圆点的位置是为了标记候选式已经被匹配了多少。点左边的部分就是已经被匹配的部分
打完点后,将这些 LR(0) 项目进行分类
- 圆点出现在产生式的最右端
- 接受项目: ,直接结束
- 归约项目: ,说明分析栈里头刚好是一个可归前缀,可以归约
- 圆点不出现在产生式的最右端
- 移进项目:,即圆点后面是终结符,说明分析栈里头是活前缀,且需要移进一个终结符
- 待约项目:,即圆点后面是非终结符,说明得先把其他符号归约出 B 才能进行当前归约项目
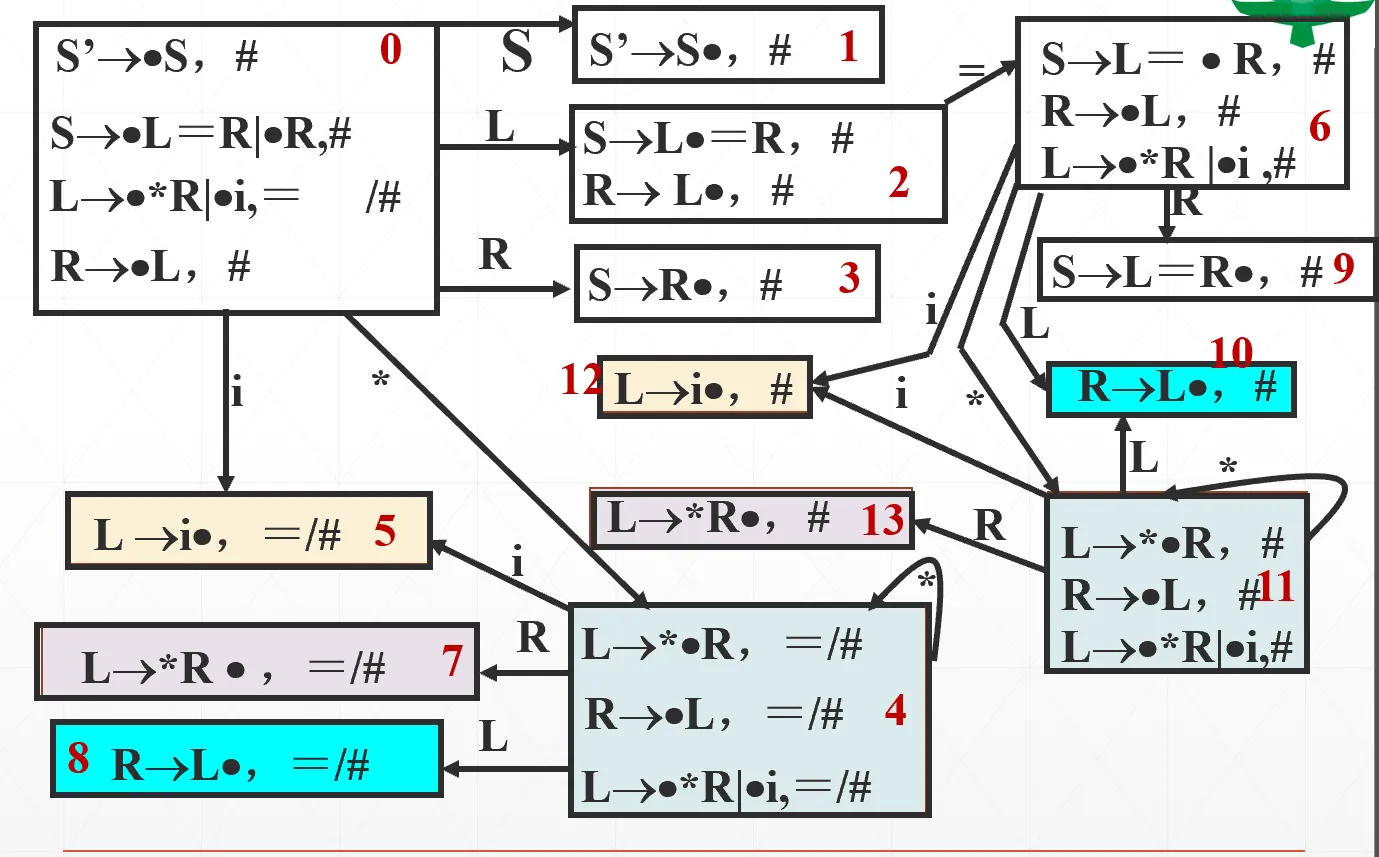
每一个 LR(0) 项目都是一个状态。据此可以构造 NFA
- 初态:(如果没有拓广文法,则初态即“圆点在候选式最左侧的、来自开始符号产生式的项目”)
- 终态:所有“圆点出现在产生式最右端”的项目(要么是归约项目,要么是接受项目)
- 状态转移:
- 若两个项目出自同一产生式(,),则从状态 i 到状态 j 存在边,识别字符即为 X
- 若状态 i 为待约项目(也即圆点后跟着的非终结符记为 ),而状态 j 为 (也即以 B 为左部的产生式的第一个 LR(0) 项目),那么状态 i 到状态 j 存在边,识别字符为 ε
然后把 NFA 确定化成 DFA(不用最小化,按 DFA 填表即得 LR(0) 分析表:对于每一个状态,看出边。
- 如果出边是终结符,则填 action 表:
- 如果当前状态是非终态,就填
- 如果当前状态是终态(归约项目),则根据对应的产生式填写 (整行都写,包括 # 列)
- 如果当前状态是终态(接受项目),则对应行的 # 列填 acc
- 如果出边是非终结符,则填 goto 表,直接写转移的状态
DFA 的每个状态都是若干个项目,DFA 的状态集则称为 LR(0) 项目集规范族 C
另一个求项目集规范族的方法,用 项目集闭包函数(clousure 函数) 和 项目集转移函数(go 函数),看 ppt264,直接从产生式就可以做,不需要写项目集、NFA、DFA。本质和刚才的步骤是一样的,但是快很多
- 基本项目:
- clousure 函数求法:如果点后面是非终结符,则要把以这个非终结符为左部的产生式,最左端打点后加入项目集闭包;如果点后面不是非终结符则不用动。重复直到没有新的项目加入
- go 函数求法:对于一个项目集闭包,看一下点后面跟了什么,跟了几种东西就有几个 go 函数。例如下图中,项目集闭包 当中,点的后面跟了 A、a、b,于是就有三个 go 函数。读入 a 之后,对应的那个项目当中圆点就要右移,然后再求一次闭包

最终得到的其实就是 DFA,其中 项目集规范族 就是 状态集,go 函数 就是 状态转移函数,初态就是基本项目的闭包。
和 LL(1) 分析表一样,表格项具有唯一性时可以定义 LL(1) 文法,所以这就可以定义 LR(0) 文法:
曰:如果文法对应的 DFA 的每一个状态内(即项目集内)性质唯一,则称为 LR(0) 文法,即:
- 不存在“既有移进项目又有归约项目”的状态(否则无法确定是移进还是归约。这称为移进 - 归约冲突)
- 不存在“含有多个归约项目”的状态(否则无法确定用哪一个产生式进行归约。这称为归约 - 归约冲突)
- 不存在“既有归约项目又有接受项目”的状态(否则无法确定是归约还是停止。这称为接受 - 归约冲突)
或者简单说,就是“如果一个项目集里头含有归约项目,那么这个项目集里就只能有这一个项目”
SLR(1) 分析#
刚才当遇到归约项目的时候,整行都要填 ,而我们又知道归约动作是引起冲突的主要原因。因此我们需要限制 的填写。
规定:在填归约动作的时候,求产生式左部的 FOLLOW 集,只有属于 FOLLOW 集的终结符才填 ,其他都置空。这就是 SLR(1) 分析表。S 的意思是 Simple,1 的意思是往后看一个字符,“往后看一个”就是靠 Follow 集实现的
这样子就只有“能被推导出来的句型”可以做归约动作,其他时候说明该终结符一定不可能出现在后面,这时候做状态转移或者直接报错,可以减少很多冲突。
同样的可以定义 SLR(1) 文法:文法的 SLR(1) 分析表没有多重表项的时候 称为 SLR(1) 文法
LR(1) 分析#
例子

写出识别可归前缀的 DFA(这个例子很好 建议练一下):
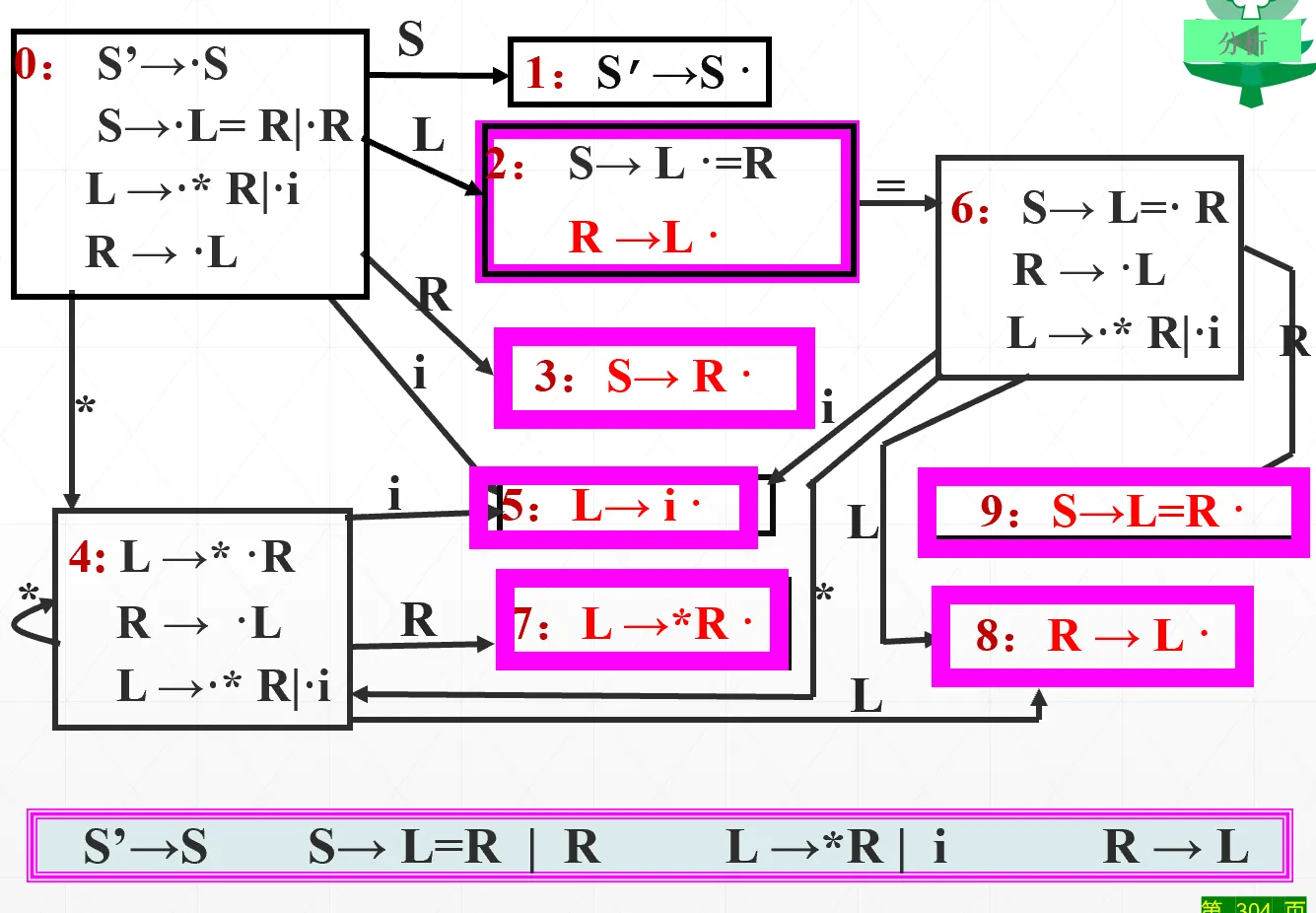
状态 2 既有归约项目又有移进项目,LR(0) 肯定是不行了。再看 SLR(1),状态 2 当中要填 ,那么就要看左部 的 Follow 集,求出来 Follow(R)={#, =}。这就又有问题了,因为读入等号可以转移到状态 6,这时 action 表的 (2, =) 项既要填 又要填 ,又冲突了
其原因在于,SLR(1) 确实看了后一个字符,排除掉了那些不可能出现在 follow 集当中的终结符;但是他没有考虑已经进入符号栈当中的东西。完全有这样一种可能:当符号栈里头已经有了一串 的时候,等号不可能接在 R 的后面,此时状态 2 遇上等号的时候一定是走
定义:文法的一个 LR(k) 项目,就是一个 LR(0) 项目再加上 k 个终结符(或井号)。这 k 个终结符称为“搜索符串”
定义:当存在规范推导 ( 是终结符串)时,称 LR(1) 项目【 ,】对于活前缀 有效;其中 称为搜索符,当 时 ,否则 。注意,规范推导的最后一步是一步从 A 推导出 αβ
例子:
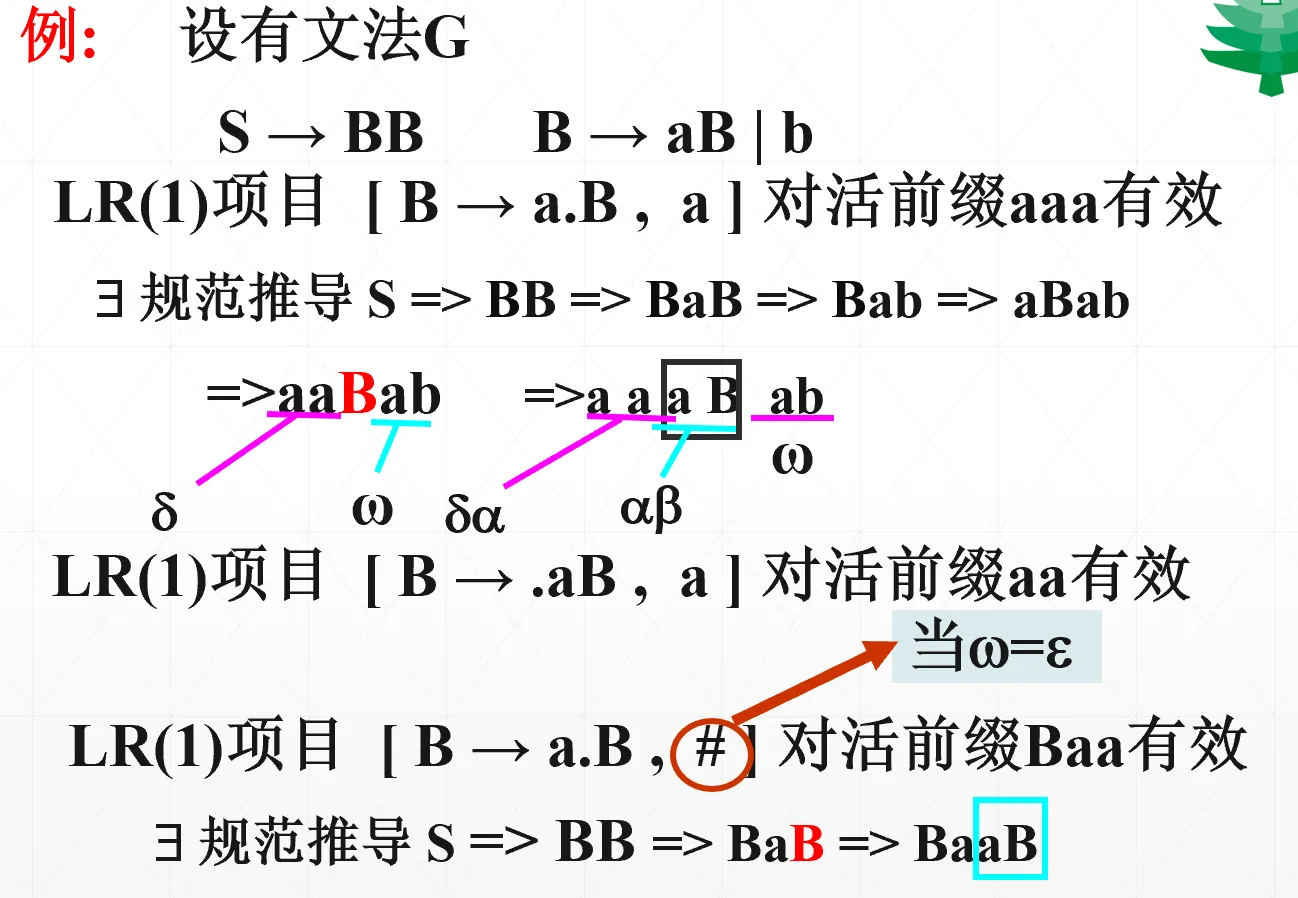
比如我想要知道 LR(1) 项目【】是否对活前缀 aaa 有效。根据圆点可知,候选式里已经有一个 a 在栈里头了,活前缀还剩下 aa,产生式左部是 B,搜索符是 a,所以我就需要求 aa/B/a… 这个句型(之后就只需要使用这个产生式一步推导出 aa/aB/a…),所以用最右推导推出这个句型。如果能推导出来则说明有效。否则无效。
例子:
例如刚才冲突的那个状态 2。把 LR(0) 项目 根据 Follow(R) 拆成两个 LR(1) 项目,现在看他们对 L 是否有效
【】【】
- 第一个项目:根据圆点我们知道,L 已经在栈里头了,所以活前缀剩下的就是空串,产生式左部是 R,搜索符是 # ,所以我就需要求 /R/# 这个句型。这个推导很简单,直接 S->R 就行了。所以他对 L 有效
- 第二个项目:搜索符是 =,所以我就需要求 /R/=… 这个句型。而规范推导推不出这个句型,所以他对 L 无效
LR(1) 项目也有项目集规范族。求法和 LR(0) 几乎是一样的
- 基本项目: 【】
- clousure 函数求法:如果点后面是非终结符(例如项目【】),则要把以这个非终结符为左部的产生式,最左端打点后,对把 First(βa) 当中的每一个终结符都构建一个 LR(1) 项目并加入项目集闭包;如果点后面不是非终结符则不用动。重复直到没有新的项目加入
- go 函数求法:对于一个项目集闭包,看一下点后面跟了什么,跟了几种东西就有几个 go 函数。例如下图中,项目集闭包 当中,点的后面跟了 A、a、b,于是就有三个 go 函数。读入 a 之后,对应的那个项目当中圆点就要右移,然后再求一次闭包,搜索符继承过去即可
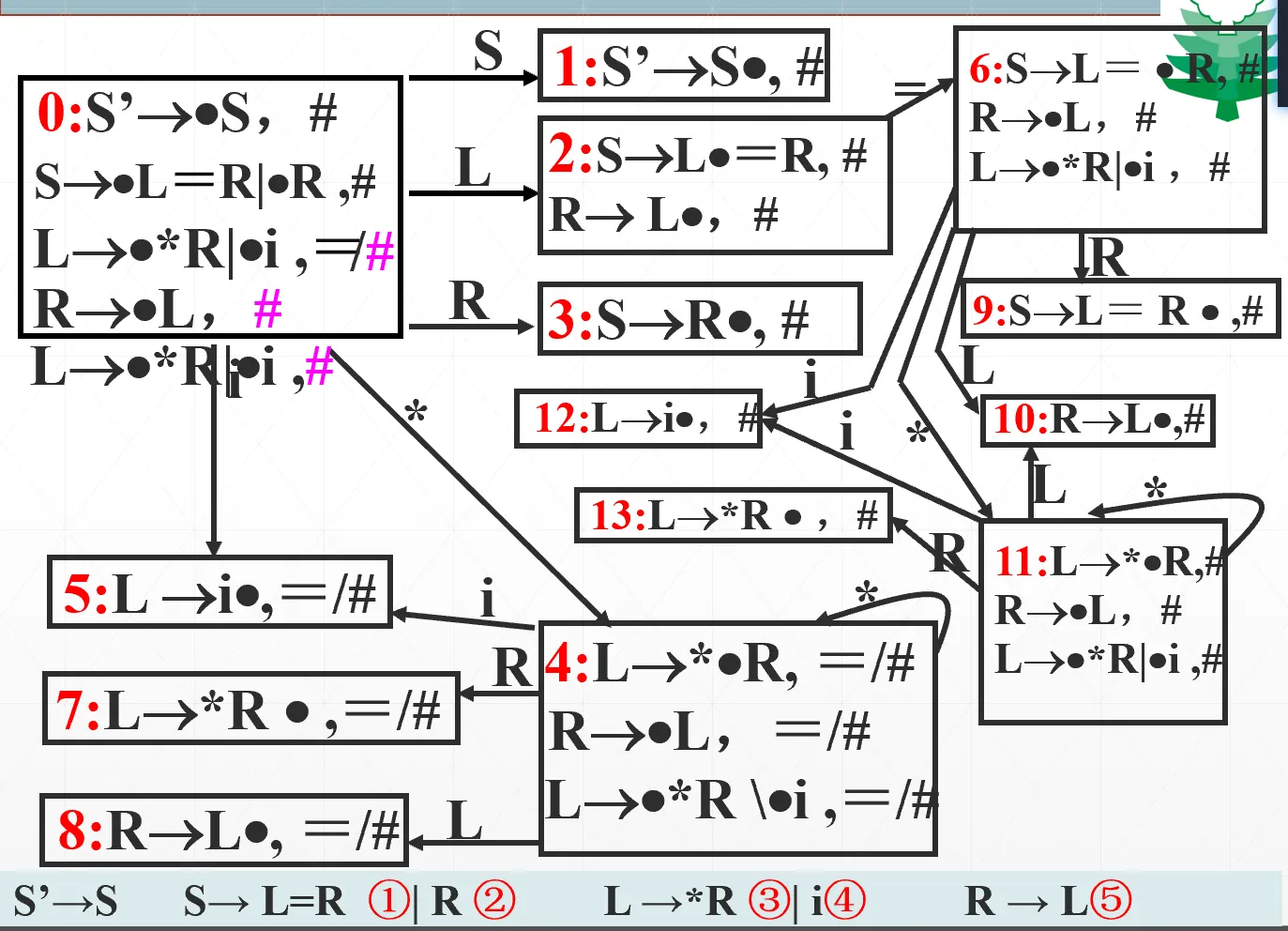
特别注意,不同的搜索符对应的是不同的 LR(1) 项目,这一点和 LR(0) 不一样,所以状态 0 当中,第三条和第五条是两个不同的 LR(1) 项目。可以合并。
状态 11 是状态 4 的子集
终于要来填表格了。
- 如果出边是终结符,则填 action 表:
- 如果当前状态含有待约项目/移进项目,就填
- 如果当前状态含有归约项目,则根据对应的产生式,只在搜索符那几列填写
- 如果当前状态含有接受项目,则对应行的 # 列填 acc
- 如果出边是非终结符,则填 goto 表,直接写转移的状态
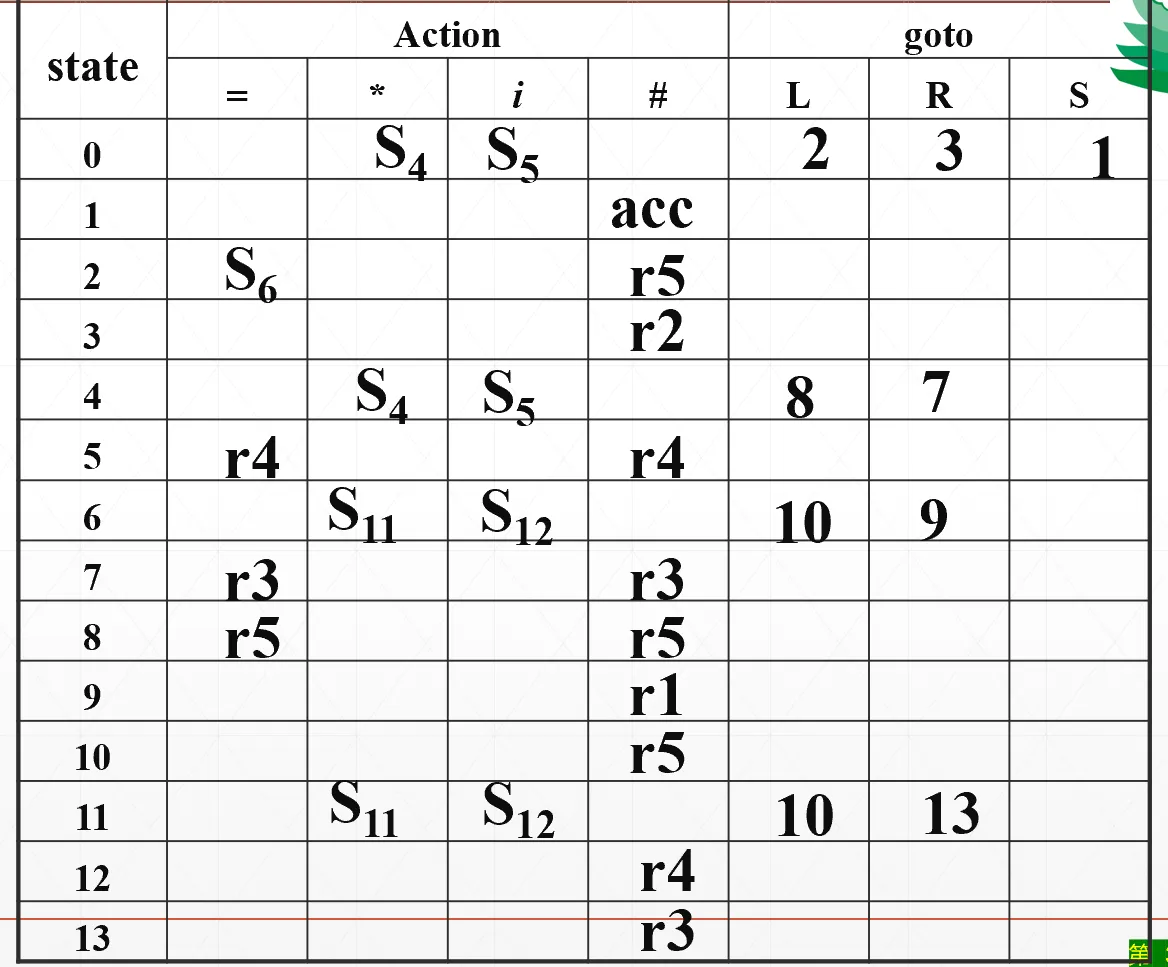
同样的,LR(1) 分析表当中没有多重表项的时候称为 LR(1) 文法
再一个例子(这个其实 LR(0) 就够用了)


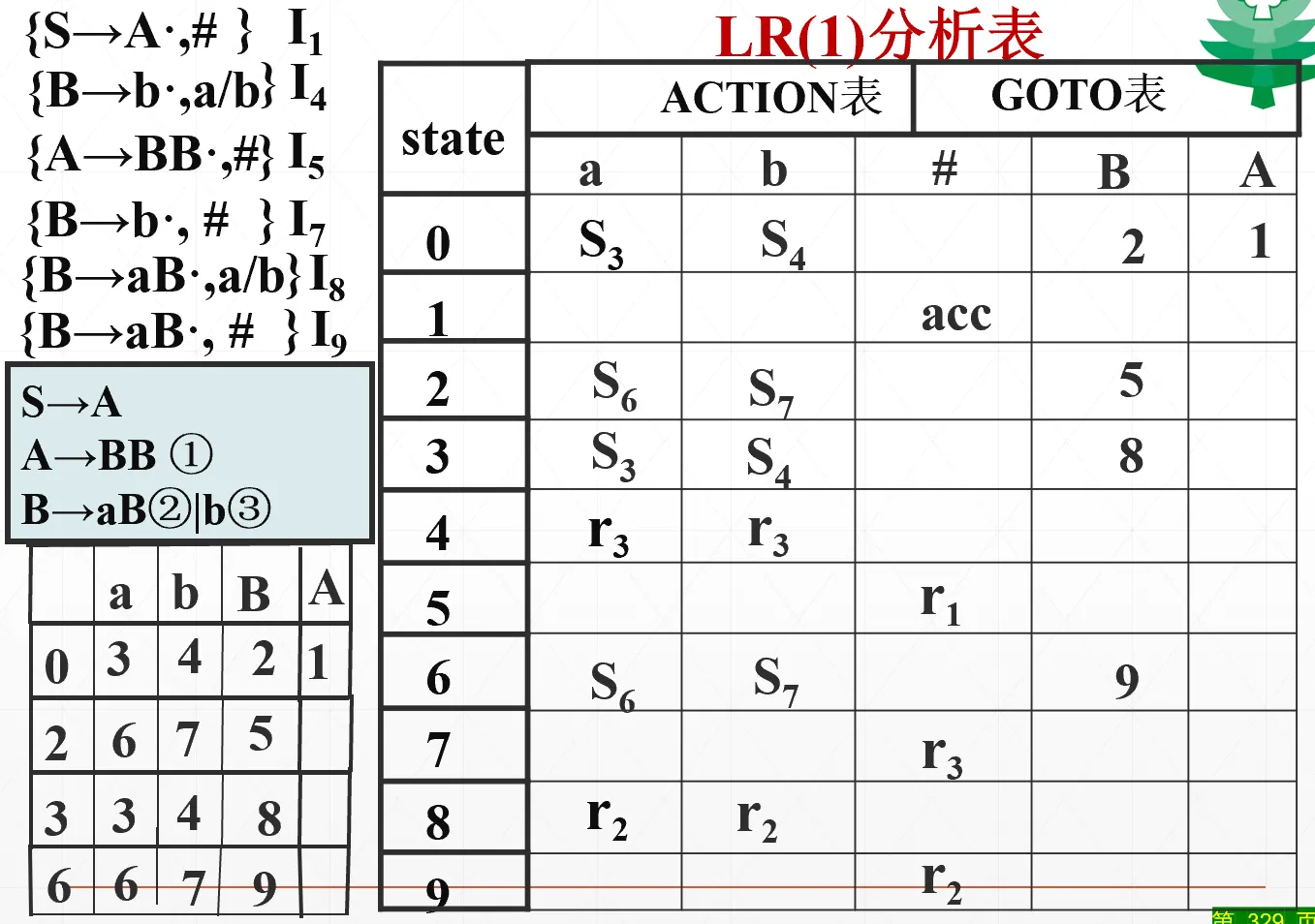
LALR(1) 分析#
LookAhead LR,是 LR(1) 的简化版本,将状态数压缩到 LR(0) 相同,但保留了 LR(1) 的“瞻前”能力,也即省内存。因此 LR(1) 分析不了的,LALR(1) 也分析不了。
观察刚才最后一个例子,我说“用 LR(0) 其实就够了”,因为有几个状态仅仅是搜索符不同而已(下图中同颜色的)
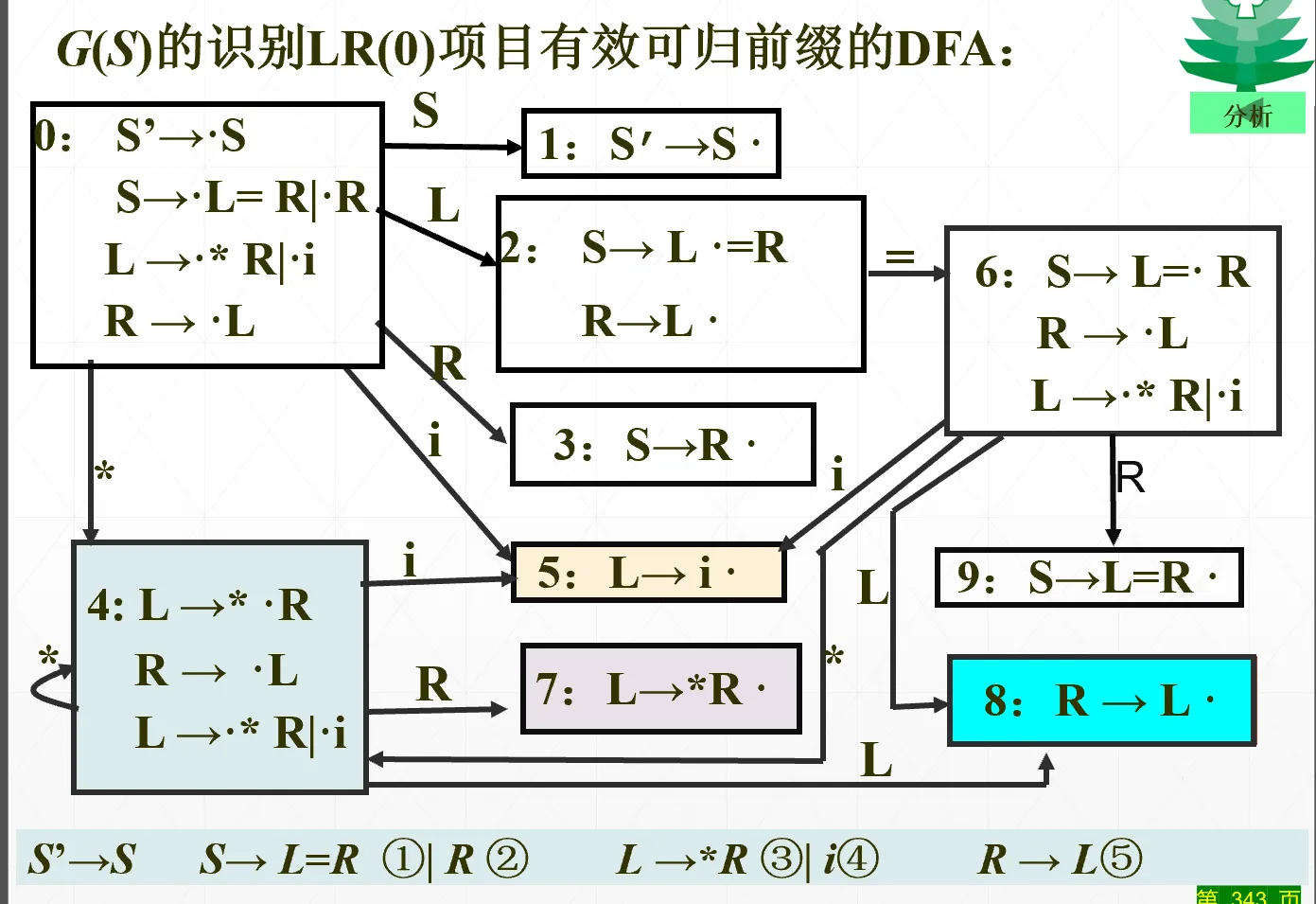
定义:如果 LR(1) 项目当中,LR(0) 项目相同、只有向前搜索符不相同,则称他们具有相同的心,或者称为同心项目集。
将 LR(1) 的所有状态,同心的合并到一起,就变成了 LALR(1) 的状态集,状态函数相应地合并就行了。
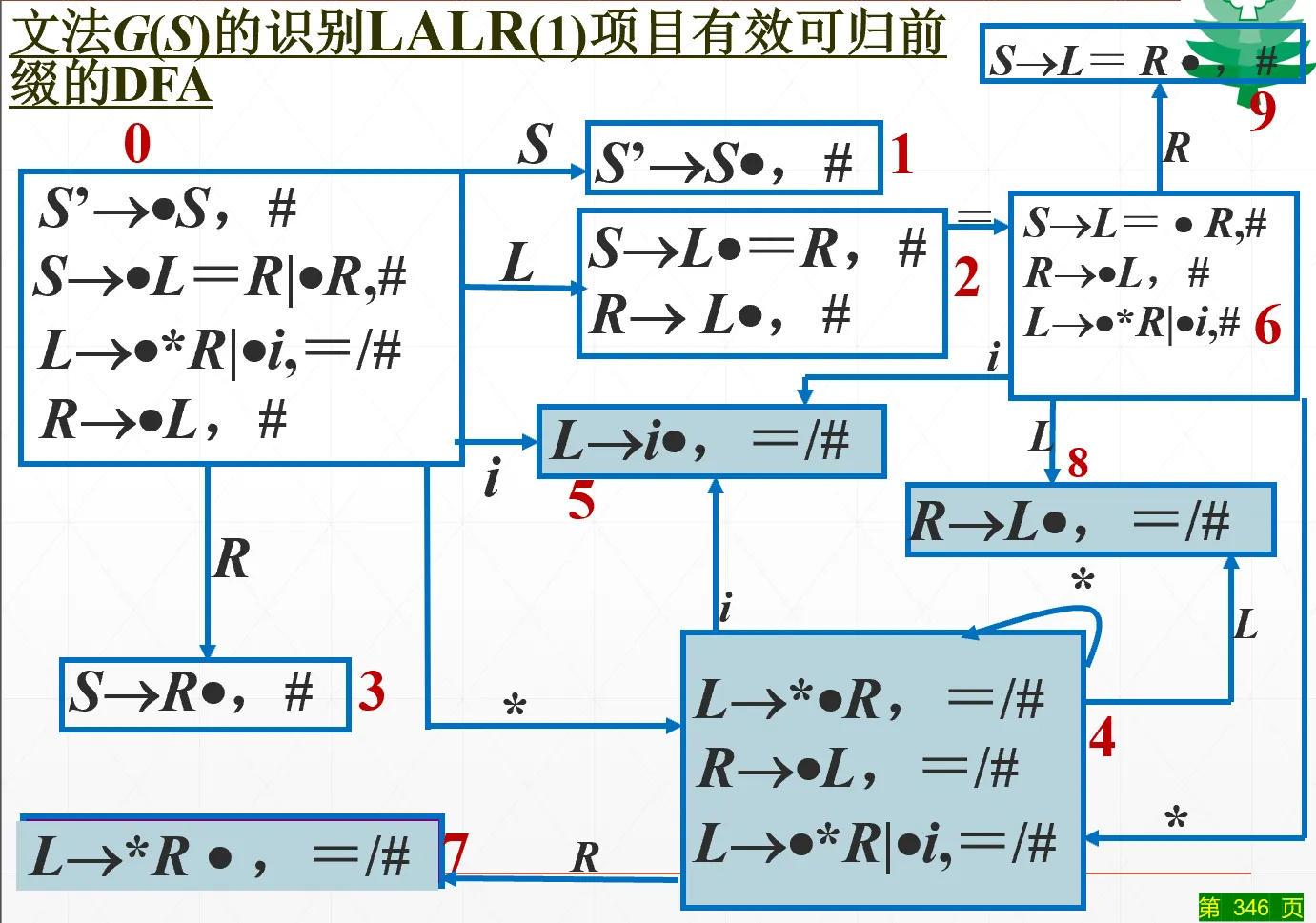
项目数和 LR(0) 一致,但是这和 LR(0) 完全不同,因为有了向前搜索符,填表方式变了。
LR(1) 合并同心项目集之后,不一定能保证不冲突,但是只可能是归约 - 归约冲突,不可能是移进 - 归约冲突。因为 LR(1) 文法保证了归约项目的搜索符集和该状态的出边集一定不交,而同心项目集的出边集一定是一样的(否则 LR(0) 部分不可能相等),所以合并之后还是不交的
总结#
判断文法属于哪一种 LR 文法:
- 先尝试做 LR(0) 分析,如果发现归约项目不是单独成项的:
- 则尝试做 SLR(1),即看一下冲突的时候,左部的 Follow 集是否不交,如果还是冲突:
- 尝试做 LR(1),即需要重新做一遍带有搜索符的语法分析
LR 分析与二义文法#
任何一个二义文法都不是一个 LR 文法
LR 分析的错误处理与恢复、#
策略:
- 局部化恢复(主要看这个)
- 紧急恢复方式:每次发现错误时,抛弃一个输入符号,直到输入符号属于某个指定的同步符号集合为止(例如代码界限符,分号、大括号、end 等)。在分析到某一含有错误的短语时,分析程序认为含有错误的短语是由某一非终结符 A 所推导出的,短语的一部分已处理,放在栈顶部,剩下未处理的在输入串,分析程序跳过这些剩余符号,直至找到 A 的跟随字符为止,同时把栈顶内容逐个移去, 直至找到某个状态 q,GOTO(q,A) 对应一新状态,将 GOTO(q,A) ,A 压入栈。保证接下来能够继续推进分析过程
- 短语级恢复:发现错误时,对剩余符号串做局部校正,使用可以使编译器继续工作的输入串代替剩余输入的前缀。在输入串的出错点采用插入、删除或修改的方法。关键是选择合适的替换串。怎么替换呢:带错误处理的 LR 分析表。原本空白格子就是分析错误,现在在空白格填入 ,表示使用第 i 条产生式进行短语恢复。这块直接看 ppt 379 页开始。感觉是需要分析语义的,“当前状态下期待读入一个什么字符”,似乎是要一个一个空格看
- 出错产生式,扩充语言的文法 增加产生错误结构的产生式,分析中可以直接识别处理错误
- 全局纠正全几乎扩充语言的文法